Paper
DeepSeek-R1 Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (DeepSeek-R1 테크니컬 리포트 논문 읽기)
남디윤
2025. 1. 28. 21:28
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
날짜: 2025년 1월 30일
- https://arxiv.org/pdf/2501.12948
- technical report 논문?!?! 이고 방법론까지만 읽어보았습니다.
- 요즘 난리난 그 딥시크입니다
- 특징으로는
- DeepSeek-R1-Zero: 초반 학습할 때 SFT 방식 아니고 강화학습 방식으로 학습
- 근데 DeepSeek-R1-Zero가 몇 가지 문제가 있어서 해결방안 탐색해서 진행한게 DeepSeek-R1
- DeepSeek-R1에서는 콜드스타트 데이터와 강화학습을 좀 더 발전시켜서 학습 + RL 학습 성능이 수렴되면 그 이후에 추가적인 SFT 학습
- distillation 진행하고 오픈소스로 공개했는데 성능이 기가 막히다고 함 (distillation 에서는 심플하게 DeepSeek-R1로 생성한 샘플 학습, RL 없음)
- 딥시크 때문에 openai 랑 meta 랑 뭐 등등 다 난리라는데 ㅎㅎ..
- RL converges: 강화학습(Reinforcement Learning) 과정에서 모델이 훈련을 계속 진행한 후, 성능이 일정 수준에 도달하고 나서 더 이상 큰 변화가 없거나 성능 향상이 거의 멈추는 상태
Abstract
- DeepSeek-R1-Zero, DeepSeek-R1
- DeepSeek-R1-Zero
- 눈에 띄는 추론 능력
- SFT 없이 대규모 강화 학습(RL)을 통해 훈련된 모델
- 가독성이 낮고 언어 혼합과 같은 문제에 직면
- DeepSeek-R1
- RL 이전에 다단계 훈련과 콜드 스타트 데이터를 통합
- 추론 작업에서 OpenAI-o1-1217과 견줄 만한 성능을 달성
- DeepSeek-R1-Zero
- DeepSeek-R1-Zero, DeepSeek-R1, DeepSeek-R1에서 Qwen과 Llama를 기반으로 증류된 여섯 개의 밀집 모델(1.5B, 7B, 8B, 14B, 32B, 70B)을 오픈 소스로 공개
1. Introduction
- post-training: 전체 훈련 파이프라인의 중요한 구성 요소
- 추론 작업에서 정확도를 향상, 사회적 가치와 일치, 사용자 선호에 적응할 수 있는 것으로 입증됨
- 사전 훈련에 비해 상대적으로 최소한의 계산 자원을 요구
- 추론 능력 OpenAI의 o1 (OpenAI, 2024b) 시리즈 모델
- Chain-of-Thought 추론 프로세스의 길이를 증가시켜 추론 시간 스케일링을 처음으로 도입
- 수학, 코딩 및 과학적 추론과 같은 다양한 추론 작업에서 상당한 개선
- 그러나 효과적인 시험 시간 스케일링의 문제
- 기존 연구: 프로세스 기반 보상 모델, 강화 학습 및 몬테카를로 트리 검색 및 빔 검색과 같은 검색 알고리즘
- 그러나 이러한 방법 중 어느 것도 OpenAI의 o1 시리즈 모델과 비교할 만한 일반 추론 성능을 달성 X
- 본 연구 순수한 강화 학습(RL)을 사용하여 언어 모델의 추론 능력을 향상
- 목표: supervised data 없이 LLM이 추론 능력을 개발할 수 있는 잠재력을 탐구
- 순수 RL 프로세스를 통한 자가 진화에 중점
- DeepSeek-V3-Base를 기본 모델로 사용, GRPO를 RL 프레임워크로 활용하여 모델 성능을 향상
- 수천 단계의 RL 이후, DeepSeek-R1-Zero는 추론 벤치마크에서 뛰어난 성능
- DeepSeek-R1을 소개
- DeepSeek-R1-Zero의 문제: 가독성이 떨어지고 언어가 혼합되는 등
- 문제를 해결하고 추론 성능을 향상시키기 위해, 적은 양의 콜드 스타트 데이터를 통합, 다단게 훈련 파이프라인 도입
- DeepSeek-V3-Base 모델을 미세 조정, 수천 개의 콜드 스타트 데이터를 수집하는 것부터 시작
- DeepSeek-R1-Zero와 같이 추론 지향적인 RL을 수행
- RL 과정에서 수렴에 가까워질 때, RL 체크포인트에서 rejection 샘플링을 통해 새로운 SFT 데이터를 생성
- DeepSeek-V3에서 글쓰기, 사실 QA, 자기 인식과 같은 분야의 감독 데이터를 결합하여 DeepSeek-V3-Base 모델을 재훈련
- 새로운 데이터를 통한 미세 조정 후, 체크포인트는 모든 시나리오의 프롬프트를 고려한 추가 RL 프로세스를 진행
- ((엄청 긴 훈련 파이프라인이다ㅏ….))
- DeepSeek-R1에서 더 작은 밀집 모델로의 증류를 탐구
- Qwen2.5-32B(Qwen, 2024b)를 기본 모델로 사용, DeepSeek-R1에서의 직접 증류 → RL 적용보다 뛰어난 성과
- 큰 기본 모델에서 발견된 추론 패턴이 추론 능력 향상에 중요한 역할
- 증류된 Qwen 및 Llama(Dubey et al., 2024) 시리즈를 오픈소스로 제공
- Qwen2.5-32B(Qwen, 2024b)를 기본 모델로 사용, DeepSeek-R1에서의 직접 증류 → RL 적용보다 뛰어난 성과
1.1 Contribution
- Post-Training: Large-Scale Reinforcement Learning on the Base Model
- 감독된 미세 조정(SFT)에 의존하지 않고 기본 모델에 직접적으로 강화 학습(RL)을 적용
- DeepSeek-R1-Zero: self-verification, reflection, and generating long CoTs,
- DeepSeek-R1을 개발하기 위한 파이프라인을 소개
- 인간의 선호와 일치시키기 위한 두 개의 RL 단계
- 모델의 추론 및 비추론 능력의 seed 역할을 하는 두 개의 SFT 단계
- 감독된 미세 조정(SFT)에 의존하지 않고 기본 모델에 직접적으로 강화 학습(RL)을 적용
- Distillation: Smaller Models Can Be Powerful Too
- 더 큰 모델의 추론 패턴을 작은 모델로 증류 가능
- 작은 모델에서 RL을 통해 발견한 추론 패턴과 비교하여 더 나은 성능
- DeepSeek-R1이 생성한 추론 데이터를 사용, 여러 개의 밀집 모델을 미세 조정
- 더 큰 모델의 추론 패턴을 작은 모델로 증류 가능
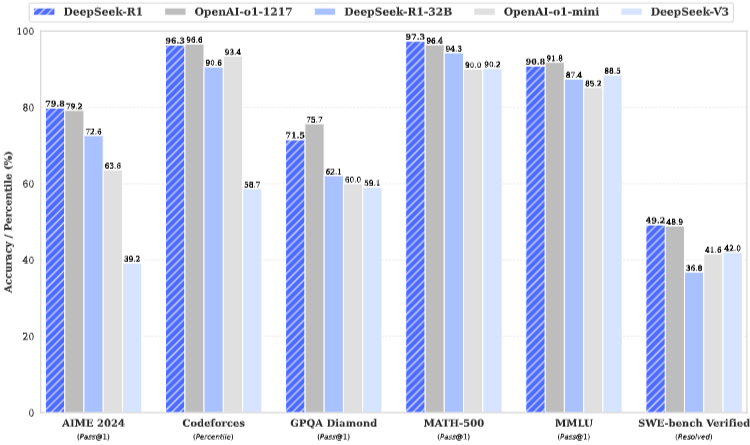
1.2. Summary of Evaluation Results
- 추론 과제:
- DeepSeek-R1이 AIME 2024, MATH-500에서 뛰어난 성능
- 코딩 관련 과제에서도 뛰어난 성능
- 지식:
- MMLU, MMLU-Pro, GPQA Diamond와 같은 벤치마크에서 뛰어난 결과
- 기존 오픈소스 모델 초과
- OpenAI-o1-1217보다 성능이 다소 낮지만, DeepSeek-R1은 다른 폐쇄형 모델을 초월
- 기타
- 창의적인 글쓰기, 일반적인 질문 응답, 편집, 요약 등을 포함한 다양한 작업에서 뛰어난 성능
- length-controlled win-rate of 87.6% on AlpacaEval 2.0
- intelligently handle non-exam-oriented queries
- 긴 맥락 이해가 필요한 작업에서 뛰어난 성능
2. Approach
2.1 Overview
- 이전 연구: 대용량의 SFT 데이터에 크게 의존
- 본 연구: SFT 사용하지 않고, 대규모 강화학습 RL을 통해 추론 능력 크게 향상
- 소량의 콜드 스타트 데이터 포함하여 성능 향상
- (1) SFT 데이터 없이 기본 모델에 RL을 직접 적용한 DeepSeek-R1-Zero
- (2) 수천 개의 긴 Chain-of-Thought (CoT) 예제로 세부 조정된 체크포인트에서 시작하여 RL을 적용한 DeepSeek-R1
- (3) Distill the reasoning capability from DeepSeek-R1 to small dense models
2.2. DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
- 강화 학습은 추론 작업에서 상당한 효과를 입증
- 하지만 기존 연구들: SFT 데이터에 많이 의존
- SFT 데이터 없이 LLM이 추론 능력을 개발할 잠재력을 탐구, 순수한 강화 학습 과정
- Reinforcement Learning Algorithm
- Group Relative Policy Optimization GRPO
- RL의 훈련 비용을 절감하기 위해, 일반적으로 정책 모델과 같은 크기의 비평가 모델을 포기
- 그룹 점수에서 기준선을 추정하는 그룹 상대 정책 최적화(GRPO)를 채택
- 각 질문 𝑞에 대해 GRPO는 오래된 정책 𝜋𝜃𝑜𝑙𝑑로부터 출력 그룹 {𝑜1, 𝑜2, · · · , 𝑜𝐺 }를 샘플링한 다음, 다음 목표를 최대화하여 정책 모델 𝜋𝜃를 최적화
- Group Relative Policy Optimization GRPO
- Reward Modeling
- reward는 학습에서 중요 요소, RL의 최적화 방향을 결정
- DeepSeek-R1-Zero를 훈련하기 위해,
- 주로 두 가지 유형의 보상으로 구성된 규칙 기반 보상 시스템을 채택
- 정확도 보상: 응답이 올바른지를 평가
- 형식 보상: 모델이 사고 과정을 ‘’와 ‘’ 태그 사이에 두도록 강제하는 형식 보상 모델을 채택
- DeepSeek-R1-Zero 개발 시 결과 또는 과정 신경 보상 모델 (outcome or process neural reward mode)을 적용 X
- neural reward model 이 대규모 강화 학습 과정에서 보상 해킹의 위험
- 보상 모델을 재훈련하려면 추가적인 훈련 리소스가 필요, 전체 훈련 파이프라인이 복잡
- Training Template
- DeepSeek-R1-Zero를 훈련하기 위해, 간단한 템플릿을 설계하는 것부터 시작
- 템플릿은 DeepSeek-R1-Zero가 먼저 사고 과정을 생성한 다음 최종 답변을 제공하도록 요구
- 의도적으로 이러한 구조적 형식으로 제약을 제한하여 특정 내용에 대한 편향이 없도록
- 반사적 사고를 강제하거나 특정 문제 해결 전략을 촉진하는 방식이 아닌
- RL 과정에서 모델의 자연스러운 발전을 정확히 관찰할 수 있도록
- Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
- Performance of DeepSeek-R1-Zero
- 그림2: RL 훈련 과정 동안 AIME 2024 벤치마크에 대한 DeepSeek-R1-Zero의 성능 궤적
- DeepSeek-R1-Zero는 RL 훈련이 진행됨에 따라 성능의 꾸준하고 일관된 향상
- 시간이 지남에 따라 모델 성능을 최적화하는 RL 알고리즘의 효율성을 강조
- 모델이 RL(강화 학습)만으로 효과적으로 학습하고 일반화할 수 있는 능력을 강조하는 주목할 만한 성과
- 다수결 투표를 통해 더욱 향상
- Performance of DeepSeek-R1-Zero
- Self-evolution Process of DeepSeek-R1-Zero
- DeepSeek-R1-Zero의 자기 진화 과정: RL이 모델의 추론 능력을 자율적으로 향상시킬 수 있는 방법
- 그림3: DeepSeek-R1-Zero의 사고 길이 지속적인 개선
- 평균 응답 길이를 자연스럽게 학습하여 더 많은 사고 시간을 활용하여 추론 과제를 해결하는 능력 향상
- 외부 조정의 결과가 아니라 모델 내부의 본질적인 발전
- 테스트 시간 계산이 증가함에 따라 정교한 행동이 나타나는 것
- 모델이 이전 단계로 되돌아가 재평가하는 반성(reflection)과 문제 해결을 위한 대안적 접근 방식을 탐색하는 행동이 자발적으로 발생
- 이러한 행동은 명시적으로 프로그래밍된 것이 아니라, 모델과 강화 학습 환경 간의 상호작용의 결과
- Aha Moment of DeepSeek-R1-Zero
- 흥미로운 현상: 모델 생성 중간 구간에서 발생하는 “아하 모먼트”
- aha moment = 자신의 추론을 재고하고 반성하는 시점
- 이 단계에서 딥시크-R1-제로는 초기 접근 방식을 재평가
- 문제에 대한 더 많은 사고 시간을 할당하는 방법을 학습
- 모델의 성장하는 추론 능력을 증명할 뿐만 아니라, 강화 학습이 예상치 못한 정교한 결과를 이끌 수 있는 매력적인 사례
- 흥미로운 현상: 모델 생성 중간 구간에서 발생하는 “아하 모먼트”
- Drawback of DeepSeek-R1-Zero
- 딥시크-R1-제로는 강력한 추론 능력을 나타내고 예상치 못한 강력한 추론 행동을 자율적으로 개발
- 그러나 문제점: (예) poor readability, language mixing
- → DeepSeek-R1 : utilizes RL with human-friendly cold-start data
2.3 DeepSeek-R1: Reinforcement Learning with Cold Start
- results of DeepSeek-R1-Zero에서 영감 → 두 가지 질문
- 1) 고품질 데이터의 소량을 콜드 스타트로 포함함으로써 추론 성능을 더욱 향상시키거나 수렴 속도를 가속화가 가능할까
- 2) 명확하고 일관된 사고의 흐름(Chain of Thought, CoT)을 생성할 뿐만 아니라 강력한 일반 능력을 보여주는 사용자 친화적인 모델을 어떻게 훈련할 수 있을까
- → 딥시크-R1을 훈련하기 위한 파이프라인을 설계 (4단계로 구성)
- Cold Start
- DeepSeek-R1-Zero와 다르게, DeepSeek-R1에서
- 훈련의 초기 불안정한 콜드 스타트 단계를 방지하기 위해
- fine-tune the model as the initial RL actor 하기 위해, 길게 이어진 CoT 데이터를 소량 수집 및 구성
- 몇 가지 방식:
- using few-shot prompting with a long CoT as an example
- directly prompting models to generate detailed answers with reflection and verification
- gathering DeepSeek-R1-Zero outputs in a readable format
- refining the results through post-processing by human annotators
- 수천 개의 콜드 스타트 데이터를 수집, RL의 시작점으로 딥시크-V3-베이스를 세밀하게 조정
- DeepSeek-R1-Zero 와 비교했을 때, cold start data의 장점
- Readability 가독성:
- DeepSeek-R1-Zero의 주요 제약 사항 중 하나는 그 내용이 종종 읽기 적합하지 않다는 것, 응답은 여러 언어가 혼합되거나 사용자에게 답변을 강조하기 위한 Markdown 형식이 부족
- DeepSeek-R1의 콜드 스타트 데이터를 생성 시, 각 응답의 끝에 요약을 포함하는 가독성 있는 패턴을 설계, 읽기 친화적이지 않은 응답을 필터링
- |special_token||special_token|
- reasoning_process은 쿼리에 대한 CoT이며, summary은 추론 결과를 요약하는 데 사용
- Potential 잠재력:
- cold-start data with human priors (인간의 경험이나 지식을 반영한 초기 데이터) 를 사용
- 반복적인 훈련을 통해 DeepSeek-R1-Zero보다 더 나은 성능
- Readability 가독성:
- DeepSeek-R1-Zero와 다르게, DeepSeek-R1에서
- Reasoning-oriented Reinforcement Learning
- DeepSeek-V3-Base를 콜드 스타트 데이터로 미세 조정한 이후, DeepSeek-R1-Zero에서 사용된 것과 동일한 대규모 강화 학습 훈련 과정을 적용
- 특히 코딩, 수학, 과학 및 논리 추론과 같은 명확한 솔루션이 정의된 문제를 포함 / 추론 집약적인 작업
- 훈련 과정 중, CoT가 언어 혼합을 자주 보이는 것을 관찰
- 특히 RL 프롬프트가 여러 언어를 포함할 때
- 언어 혼합 문제를 완화하기 위해
- RL 훈련 중에 타겟 언어 단어의 비율로 계산되는 언어 일관성 보상을 도입
- 비록 ablation experiments, 이러한 정렬이 모델 성능의 약간의 저하로 이어짐
- 이 보상은 인간의 선호에 부합 (벤치마크에서 저하됐어도 인간이 더 선호하는 모델이라는 뜻)
- 추론 작업의 정확성과 언어 일관성에 대한 보상을 직접 합산하여 최종 보상을 형성
- DeepSeek-V3-Base를 콜드 스타트 데이터로 미세 조정한 이후, DeepSeek-R1-Zero에서 사용된 것과 동일한 대규모 강화 학습 훈련 과정을 적용
- Rejection Sampling and Supervised Fine-Tuning
- RL converges 이 오면, 체크포인트를 사용하여 이후 라운드를 위한 SFT 데이터를 수집
- 초기 콜드 스타트 데이터: 주로 추론에 초점
- 이 단계: 모델의 작문, 역할 수행 및 기타 일반적인 작업 능력을 향상시키기 위해 다른 도메인에서 데이터를 포함
- 다음과 같은 데이터 생성
- Reasoning data
- 거부 샘플링 Rejection Sampling을 통해 생성
- 이전 단계: 규칙 기반 보상만 사용
- 이번: 생성적 보상 모델을 사용하여 실제 값과 모델 예측을 DeepSeek-V3에 제공하여 판단 받음
- 혼합 언어, 긴 단락, 코드 블록을 포함한 사고의 연쇄를 필터링하고, 각 프롬프트에 대해 여러 응답을 샘플링하여 정확한 응답만을 유지
- 총 약 60만 개의 추론 관련 훈련 샘플을 수집
- Non-Reasoning data
- 작문, 사실 기반 QA, 자기 인식 및 번역과 같은
- DeepSeek-V3 파이프라인을 채택, DeepSeek-V3의 SFT 데이터셋의 일부를 재사용
- 특정 비추론 작업에 대해서는, 질문에 답하기 전에 잠재적인 사고의 연쇄를 생성하기 위해 DeepSeek-V3를 호출
- 간단한 쿼리에 대해서는, CoT 없이 바로 답변을 제공하며, 약 20만 개의 비추론 훈련 샘플이 수집
- RL converges 이 오면, 체크포인트를 사용하여 이후 라운드를 위한 SFT 데이터를 수집
- Reinforcement Learning for all Scenarios
- 모델을 인간의 선호와 더욱 일치시키기 위해,
-
- model’s helpfulness and harmlessness 유용함과 해로움 없음 측면을 ****동시에 향상시키고
-
- 추론 능력을 정제하기 위해
- → 2차 강화 학습 단계 구현
-
- 모델은 다양한 프롬프트 분포와 보상 신호를 활용해 훈련
- 추론 데이터의 경우, 수학, 코드 및 논리 추론 도메인에서 학습 과정을 안내하기 위해 규칙 기반 보상을 사용하는 DeepSeek-R1-Zero에 설명된 방법론을 준수
- 일반 데이터의 경우, 인간의 선호를 포착하기 위해 보상 모델에 의존 (모델이 더 사람처럼 생각하고, 대화에서 적절하게 반응하도록)
- 사용하는 프롬프트 분포와 선호 쌍(preference pairs)을 DeepSeek-V3 pipeline과 동일하게 적용
- 모델을 인간의 선호와 더욱 일치시키기 위해,
2.4 Distillation: Empower Small Models with Reasoning Capability
- DeepSeek-R1으로 큐레이션한 80만 개 샘플을 사용하여 Qwen (Qwen, 2024b) 및 Llama (AI@Meta, 2024)와 같은 오픈 소스 모델을 직접 미세 조정
- 증류된 모델의 경우, 우리는 SFT만 적용하며 RL 단계를 포함 X