Paper
[논문 읽기 #7] Pattern-based Time Series Semantic Segmentation with Gradual State Transitions
남디윤
2024. 5. 23. 17:50

모든 내용을 포함하고 있지 않습니다.
필요&중요 포인트만 요약한 내용입니다. (발표자료였음)
Time Series Segmentation 깃헙
- 프로젝트에서 한 시계열 안에 구간 분리(라벨)를 비지도 방식으로 진행해야해서 subsequence clustering, time series seperation 등을 찾아보다가 time series segmentation 이라는 분야가 있다는 것을 알게 되었습니다.
- 의미론적 분할 semantic segmentation 으로도 알려져있습니다.
- 연구와 연구의 코드가 함께 있는 괜찮은 깃헙을 찾아 첨부합니다.
- 깃헙의 introduction도 의미 있어서 정리해보자면,
- semantic segmentation 은 많은 영역의 연구와 연관
- 시계열 세분화, 시계열 변화점 감지 및 시계열 이상/이상탐지 간의 경계 모호
- 시계열에서 정보 압축 프로세스로 간주 가능성
- 인간 동작 시계열 데이터는 모션 프리미티브 분해 작업과 연관
- 시계열 세분화에 대한 논문은 다소 미온적
- 딥러닝이 지배적이지 않음. 고전적이지만 견고한 알고리즘 중에는 오늘날에도 여전히 경쟁력이 높음
해당 깃헙을 중심으로 한동안은 팀원분들과 리뷰 논문 정독 + 최신 논문 정독 + 프로젝트 적용 진행예정입니다.
오늘은 그 중에서 한 논문을 정독했습니다.
Pattern - based다 보니 지금까지 많이 소개드린 SAX 기법이 적용된 논문이었습니다.
논문 기본 정보
Pattern-based Time Series Semantic Segmentation with Gradual State Transitions
- SDM 2024 (4월 18일)
- Keyword: Time Series Segmentation
- 코드, 데이터셋 공개
1. Introduction & Related Works
- 시계열 데이터에서 의미 있는 시간 간격을 자동으로 식별하는 것이 시계열 의미 분할의 목표
- 예) 인간 활동 인식 – 시계열 하나에서 앉거나 서 있는 활동에 대한 시계열 분할
- 기존 방법들1
- 대부분 변화점 감지에 초점 (이산 상태 전환 분석 = 갑작스러운 변화),
- 실제 응용에서는 상태가 점진적으로 변화하는 경우가 많음
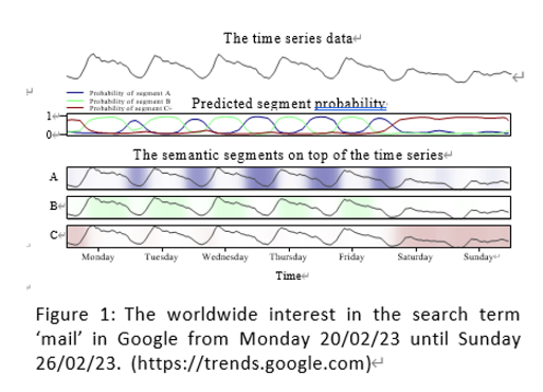
- 예) 구글 “메일“ 에 대한 검색 추이
- (A) 관심(검색량)이 높은 근무 시간,
- (B) 관심(검색량)이 잠시 감소한 주중 밤,
- (C) 감소 추이가 더 긴 주말
- 본 논문: 점진적 변화 감지 방법론 제안
- 기존 방법들2
- 예전: 특정 응용에 초점
- 최근: 도메인 독립적
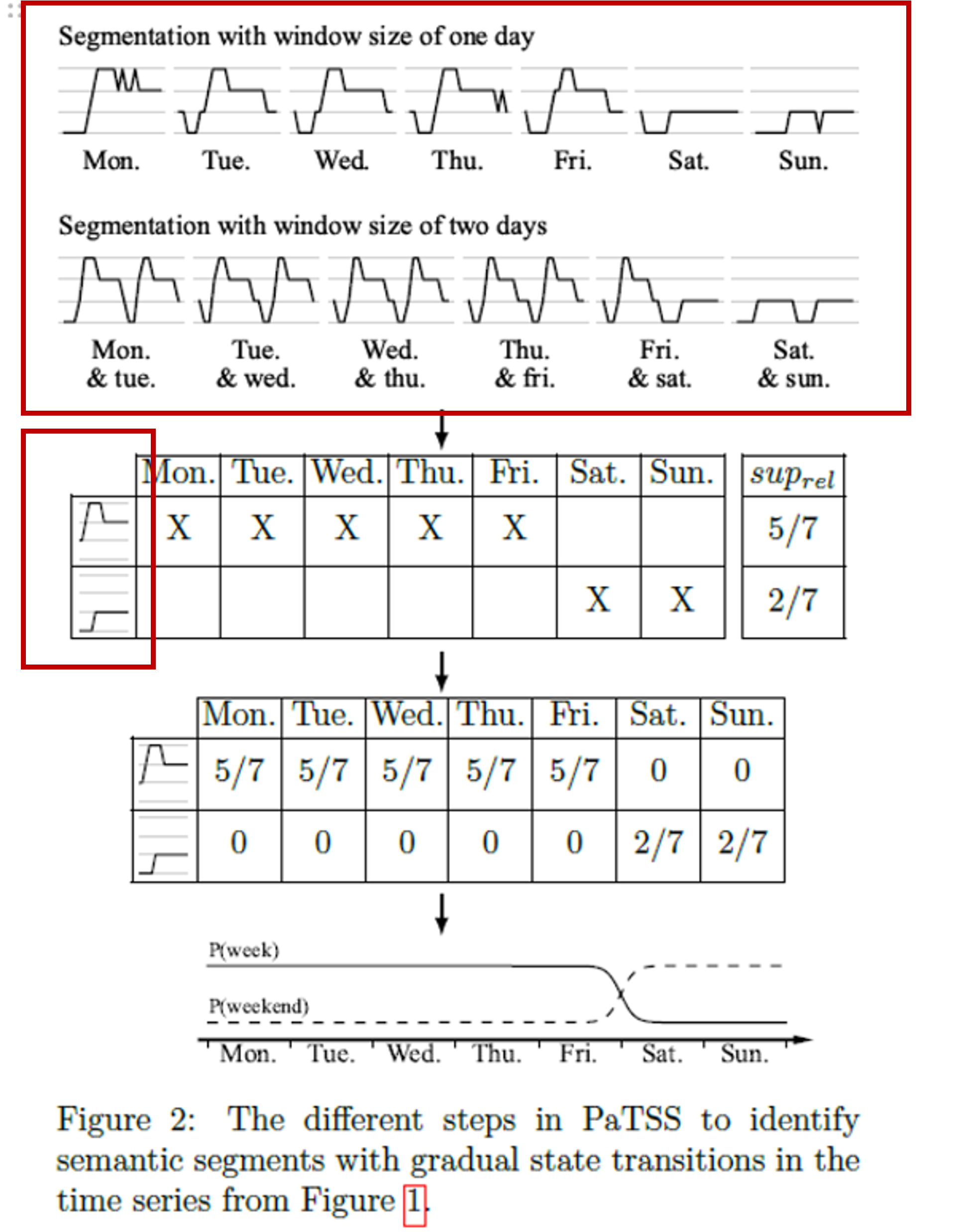
2. 방법론 PaTSS
- 세 가지 단계
- 1. 빈번한 패턴 마이닝 (Frequent Pattern Mining)
- 시계열 데이터의 상징적 변환:
- SAX 방법 사용
- 연속적인 시계열 데이터를 사전 정의된 알파벳 크기 (몇 개로 변환할지) 에 따라 상징적으로 축약
- 다중 해상도 슬라이딩 윈도우
- 다양한 길이의 슬라이딩 윈도우 적용, 다양한 크기의 subsequence 추출
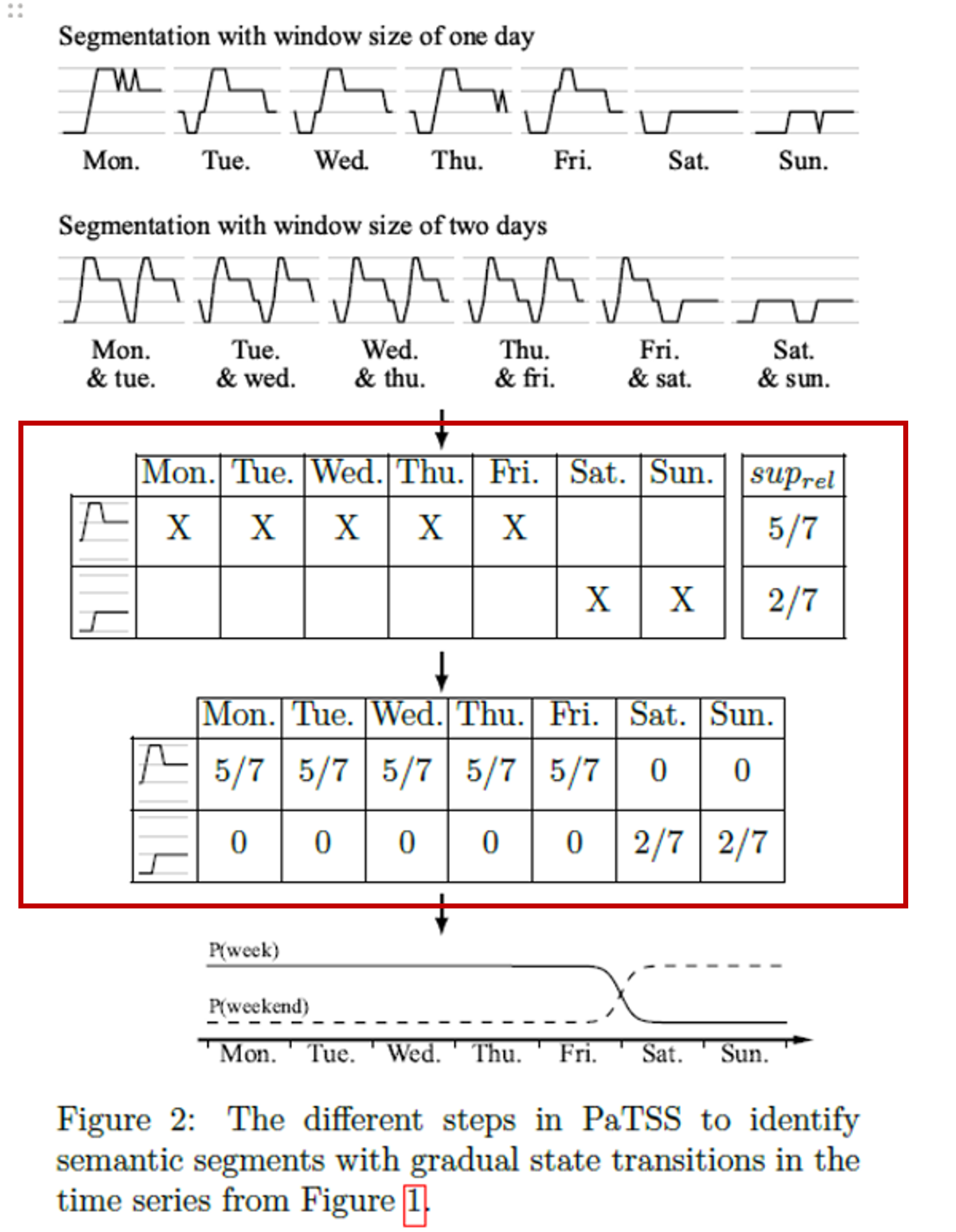
- 패턴 선택
- (상대적 지지도 계산을 통해) 데이터 세트 내에서 발생하는 빈도가 높은 패턴선택
- 2. 패턴 기반 임베딩 (Pattern-based Embedding)
- 패턴 – 시간 매핑
- 각 시간 포인트에서 발견된 패턴을 기반으로 해당 시간 포인트를 설명할 수 있는 벡터 생성
- 벡터 계산
- 패턴의 발생 빈도 고려
- 패턴이 각 시간 포인트에 가지는 중요도 수치화
- 예) 특정 패턴이 특정 시간 포인트에서 빈번히 발생하면 그 패턴의 가중치 높아짐
- 차원 축소
- 초기 임베딩 벡터는 매우 고차원 (특히 패턴이 많을수록)
- 분산 기반 선택
- 높은 분산을 가지는 패턴 사용
- 본산 높다는 것 = 시간에 따라 해당 패턴의 발생 활용이 크게 변한다는 것=의미 구간 잘 구분 특성
- 패턴 – 시간 매핑
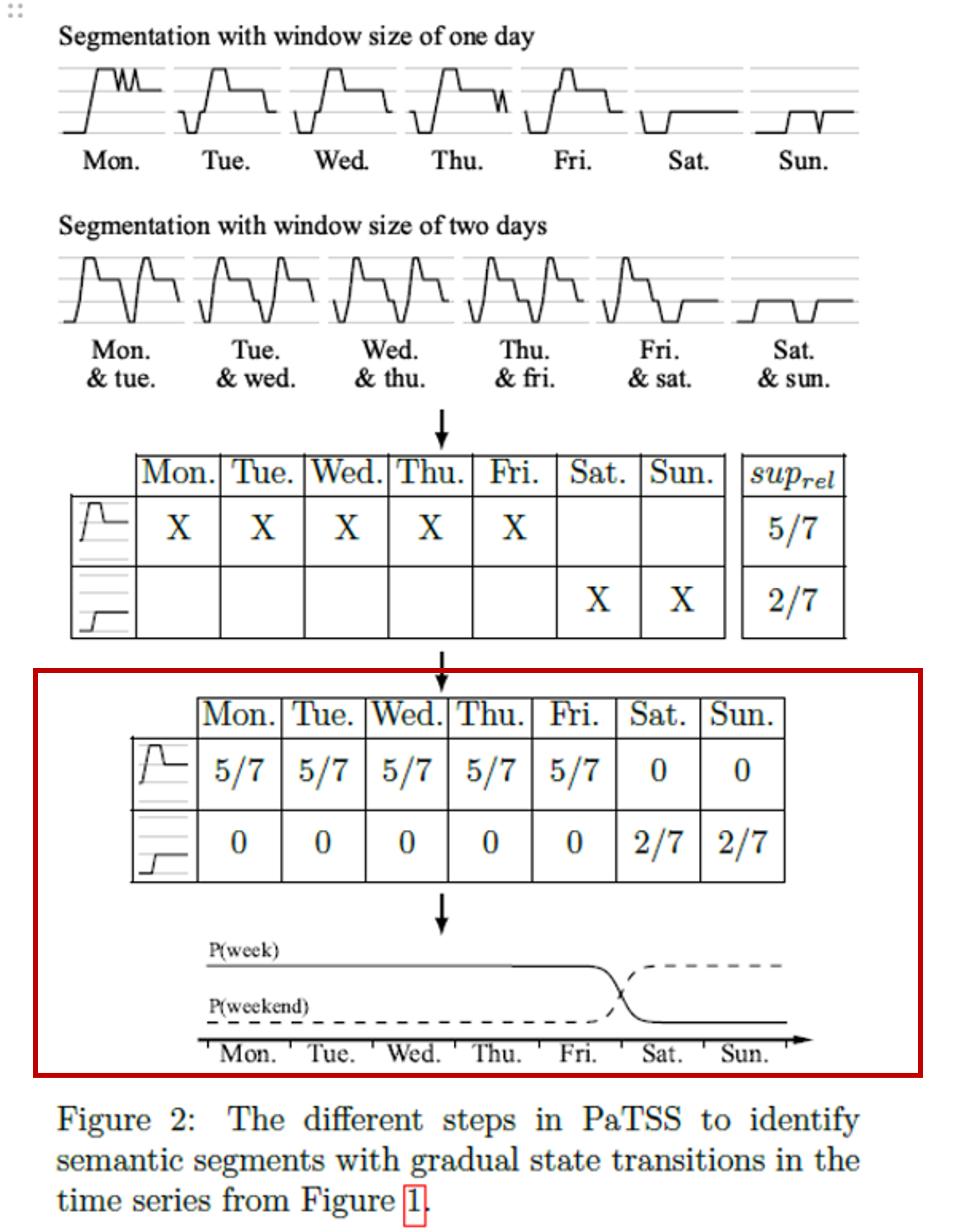
- 3. 의미 구분 (Semantic Segmentation)
- k-평균 클러스터링
- 초기 분류 제공, 임의의 k개 클러스터 군집화
- 로지스틱 회귀 모델링
- 클러스터링 결과는 로지스틱 회귀 모델의 학습을 위한 레이블 역할
- 각 시간 포인트에서 의미 구간(패턴) 발생 확률을 모델링
- 이를 바탕으로 실루엣 점수를 계산하고 k 결정
- 세그먼트 분할
- 최적의 k를 바탕으로 세그먼트 분할
- 각 시간 포인트에서 가장 높은 확률을 갖는 패턴을 찾아 연속적으로 같은 패턴이 나타나는 구간을 같은 세그먼트로 정의
- k-평균 클러스터링
3. Experiments
- 비교 방법: 기존 이산 상태 전환 분석 모델(ClaSP, FLOSS, AutoPlait 등)과 비교
- 평가 지표:
- 이산 상태 전환: 실제 변화점을 얼마나 정확히 예측하는지 측정하는 손실 함수 사용
- 점진적 상태 전환: 상태 전환의 정확한 확률적 모델링을 평가하기 위한 새로운 점수 시스템 사용
- 이산 상태 전환 손실 함수
- 예측된 변화점과 실제 변화점 사이의 거리 측정
- 절대 거리의 합이나 평균
- 점진적 상태 전환 점수 시스템
- 예측된 상태 확률 분포와 실제 상태 확률 분포 사이의 일치도 평가
- 데이터세트
- 실제 데이터
- UCR Time Series Semantic Segmentation Archive (UTSA)와 Time Series Segmentation Benchmark (TSSB)
- 다양한 시계열에서 이산적인 세그먼트 경계를 포함
- 합성 데이터 (공개되어있음)
- 특정한 상태 전환 패턴을 포함하는 데이터를 생성
- 점진적인 상태 전환을 시뮬레이션하기 위해 설계
- 실제 데이터
- 결과
- 이산 상태 전환의 경우 기존 baseline 모델들이 더 잘 감지
- 점직적 상태 전환의 경우, 본 논문의 PaTSS가 더 잘 감지함