Apache Spark RDD/Dataframe 정리

안녕하세요
BOAZ 학기 Base 세션 발표를 하며 준비했던 자료를 포스팅해보려고 합니다
제가 담당한 부분은 Spark RDD/DataFrame 이여서 이 자료를 업로드합니다 ㅎㅎ
목차
1. Apache Spark의 개념과 등장 배경
Apache Spark의 등장 배경
- 초기에는 하둡의 맵리듀스(MapReduce) 모델이 대규모 데이터 처리에 널리 사용
- 맵리듀스의 제한된 프로그래밍 모델과 반복적 작업에서의 비효율성 & 맵리듀스의 디스크 I/O 의존성
Apache Spark
- 대규모 데이터를 처리하는 데 사용되는 병렬 처리 오픈 소스 데이터 처리 엔진
- Spark는 Hadoop의 MapReduce 엔진과 비슷한 원칙을 사용하여 구축
- 주로 일괄 처리 워크로드의 속도를 높이기 위해 전체적인 인메모리 계산과 최적화에 중점
: MapReduce가 데이터를 처리한 후 디스크에 쓰거나 읽는 반면, Spark는 데이터를 메모리에 보관하여 처리 속도: → 데이터 실시간 스트리밍 처리 니즈 충족 - : 반복적인 처리가 필요한 작업에서 속도가 하둡보다 최소 100~1000배 이상 빠름
Apache Spark의 아키텍처

- 언어
- Scala: Spark의 기본 언어이자 Spark Core가 작성된 언어.
- Java: Java 기반 Spark 애플리케이션 작성 가능.
- Python: Spark의 PySpark API를 통해 Python으로 작업 가능.
- 데이터 소스
- Spark는 저장소 시스템의 데이터를 연산하는 역할만 수행
- 영구 저장소의 역할을 수행하지는 않음
- 다양한 저장소 지원 (Azure Storage, Amazon S3, Apache Hadoop, Apache Cassandra, Apache kafka 등)
- 라이브러리
- 엔진에서 제공하는 표준 라이브러리와 오픈소스 커뮤니티에서 서드파티 패키지로 제공하는 다양한 외부 라이브러리 지원
- Spark SQL: SQL 기능 담당
- 대부분의 데이터 웨어하우스보다 빠르고 분산된 ANSI SQL 쿼리를 실행
- Spark Streaming: 실시간 데이터 처리 지원
- Kafka, Hadoop과 연계 가능한 스파크 확장성
- 원하는 언어(Python, SQL, Scala, Java, R 등) 을 사용하여 Batch or Streaming 데이터 처리 가능
- MLlib: 여러 머신러닝 기법을 지원
- Tensorflow/Pytorch 등을 활용한 딥러닝 정도의 퍼포먼스는 불가
- 머신러닝 분야에서는 충분한 퍼포먼스 발휘 중
- GraphX: 그래프 분석 엔진
- Spark Core
- Apache Spark의 중심. 데이터를 여러 대의 컴퓨터에서 빠르고 효율적으로 처리할 수 있도록 도와주는 시스템
- 대용량 데이터를 처리할 때, 한 대의 컴퓨터로는 한계가 있기 때문에 여러 대의 컴퓨터가 나누어 일을 처리
- Spark Core는 이러한 분산 처리를 관리하는 역할
- API 인터페이스(자바, 스칼라, 파이썬, R 등) 기능 제공
- RDD 처리하는 로직 수행Spark의 기본적인 작업 처리 구조
- Apache Spark의 중심. 데이터를 여러 대의 컴퓨터에서 빠르고 효율적으로 처리할 수 있도록 도와주는 시스템

- Driver Program
- 클러스터 노드 중 하나에서 실행(master)
- 애플리케이션 내에서 발생하는 모든 작업의 흐름을 제어 (중앙 제어 역할 담당)
- 작업을 나누고, 클러스터의 자원을 사용하여 Worker Node에 Task를 할당합니다.
- 작업의 스케줄링 및 관리, 결과 수집 등의 역할을 수행합니다.
- SparkContext / SparkSession
- Driver Program의 핵심 구성 요소, Spark 애플리케이션의 진입점, 러스터와 상호작용하여 작업을 실행
- 작업을 분산 처리할 수 있도록 RDD(Resilient Distributed Dataset)를 여러 파티션으로 나누고, 각 파티션을 워커 노드에 할당
| 특징 | SparkContext | SparkSession |
| 주로 사용된 버전 | Spark 1.x 버전 | Spark 2.x 이후 |
| 기능 | RDD 처리만 가능 (SQL, DataFrame 등의 추가 작업 필요) | RDD, DataFrame, SQL, 스트리밍, 머신러닝, Hive 등을 통합 |
| 객체 생성 방식 | 직접 SparkContext 생성 | SparkSession에서 자동으로 SparkContext 생성 |
| 코드 복잡도 | 다양한 객체 생성 필요 (SQLContext, HiveContext 등) | 단일 객체로 모든 기능 처리 (더 간단하고 직관적) |
| 주요 사용 용도 | Spark의 기본 RDD 처리를 위한 엔트리 포인트 | Spark 2.0 이후 모든 API 통합 및 더 높은 수준의 추상화 |
- Worker Node
- Master(Driver Program)으로부터 Task를 할당받아, 해당 Task를 실행
- Task: Spark 작업의 최소 실행 단위. 각 RDD는 여러 개의 파티션으로 나뉘며, 각 파티션은 하나의 Task 로 변환됨
- 각 Task는 데이터를 처리하고, 그 결과를 Driver에 반환
- 각 Worker Node는 여러 Task를 동시에 처리, Executor는 데이터를 메모리에 캐시하거나 처리 결과를 저장
- Master(Driver Program)으로부터 Task를 할당받아, 해당 Task를 실행
- Cluster Manager
- Spark 클러스터의 자원(컴퓨팅 노드, 메모리, CPU 등)을 관리
- 리소스를 효율적으로 분배하는 역할
- SparkContext로부터 작업 요청을 받아서 적절한 Worker Node(노드)에 작업을 할당하고 자원을 배분
- 예시
| Standalone | 단일 서버 자원 관리용으로 별도 설치 없이 Spark 자체에서 제공 |
| Yarn | 여러 대 서버를 관리용으로 별도 설치가 필요하며, 가장 많이 활용 |
| Mesos | 1만대 이상의 노드에도 대응 가능한, 웹기반의 UI, 자바, C++, 파이썬 API제공 |
- 스파크 동작 과정
- Spark Driver가 main()을 실행, SparkContext/SparkSession를 생성
- SparkContext/SparkSession가 Cluster Manage와 연결
- Spark Driver가 Cluster Manager로부터 Executor 실행을 위한 리소스 요청
- SparkContext/SparkSession는 작업 내용을 task 단위로 분할하여 Executor에 전달
- 각 Executor은 작업 수행, 결과 저장
Spark Driver 내의 SparkContext/SparkSession가 job을 task 단위로 분할한 뒤, Cluster Manager로부터 할당받은 Executor로 task를 전달
2. RDD, DataFrame
: Spark의 데이터 구조, Spark의 가장 기초적인 데이터 추상화 계층
RDD (Resilient Distributed Dataset)
- 정의: 회복력 있는 분산된 데이터
- Resillient (회복력 있는, 변하지 않는): 메모리 내부에서 데이터가 손실 시 유실된 파티션을 재연산해 복구 가능
- Distributed (분산된): Spark Cluster을 통하여 메모리에 분산되어 저장됨
- Data: 데이터 파일, 정보 등
- Spark v1.0 부터 도입된 가장 기본적인 구조 (현재 3.5.2)
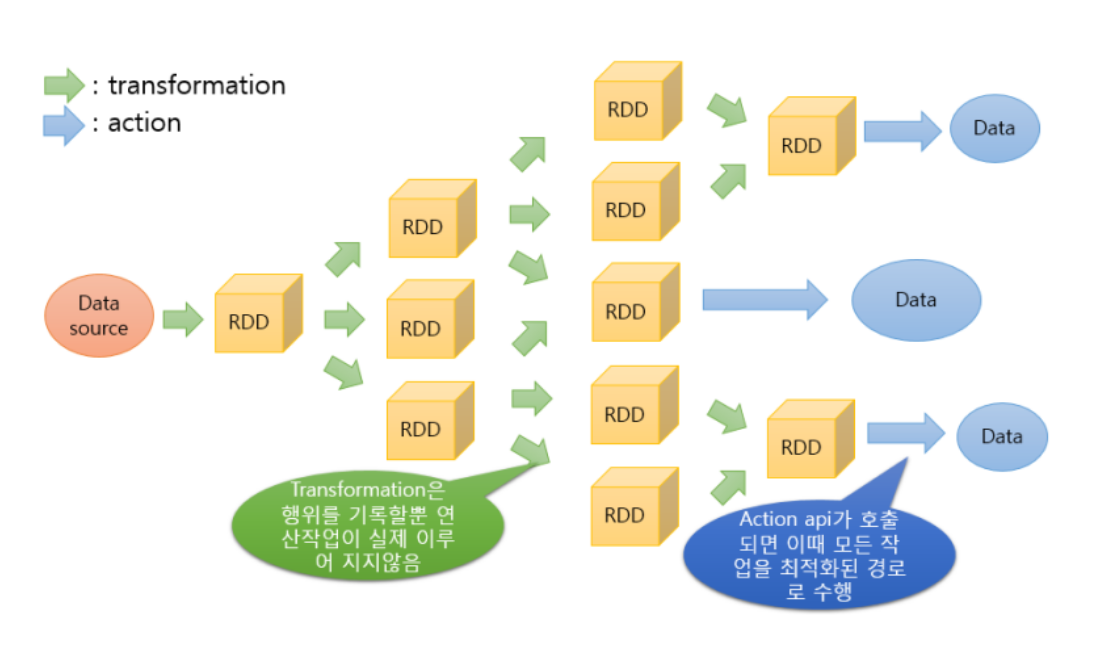
- Resillient = 불변의 특성 = Read Only
- = 특정 동작을 위해서는 기존 RDD를 변형한 새로운 RDD가 생성 필요
- → Spark 내의 연산에 있어 수많은 RDD들이 생성
- 이때 생성되는 연산 순서 = RDD Lineage (사전적 의미: 혈통): DAG(Directed Acyclic Graph) 형태
- 노드 간의 순환 cycle X, 일정한 방향성 → 각 노드간의 의존성, 노드간의 순서 중요
-
- DAG에 의하여, 특정 RDD 관련 정보가 메모리에서 유실되었을 경우, 그래프를 복기하여 다시 계산하고, 자동으로 복구 가능
- Spark는 이러한 특성을 바탕으로 Fault-tolerant(작업 중 장애나 고장이 발생하여도 예비 부품이나 절차가 즉시 그 역할을 대체 수행, 서비스의 중단이 없게 하는 특성)를 보장
- 파티션
- RDD나 Dataset를 구성하고 있는 최소 단위 객체
- 각 Partition은 서로 다른 노드에서 분산 처리
- 하나의 Task에서 하나의 Partition이 처리, 하나의 Task는 하나의 Core가 연산 처리
- 1 Core = 1 Task = 1 Partition
- 파티션 수: 코어의 수와 관련. 파티션이 많을수록 더 많은 코어에서 병렬 처리
- 파티션 크기: 할당된 메모리와 관련. 큰 파티션은 더 많은 메모리 필요.pyspark sparksession config 설정
- RDD 동작 원리
- RDD는 Spark의 가장 기본적인 데이터 단위
- Data Source로부터 최종 Data에 도달하기 위해서는 많은 RDD가 새로 생성, 변형 작업 발생
- 연산자 유형
- Transformation:
- 기존 RDD에서 새로운 RDD를 생성하는 동작 (Return = RDD)
- 실행 계획만 수립
이름 용도 map() RDD의 각 요소에 함수를 적용하고, 결과 RDD를 리턴한다. (ex. rdd.map(x: x+2) : 각 요소에 2씩 더함) filter() 조건에 통과한 값만 리턴 distinct() RDD의 값 중 중복을 제거 union() 두 RDD에 있는 데이터를 합친다. (RDD간 합집합) intersection() 두 RDD에 모두 있는 데이터만을 반환한다. (RDD간 교집합)
- Action :
- 기록된 모든 작업을 실제 수행하는 연산자 (Return = 데이터 또는 실행 결과)
이름 용도 collect() RDD의 모든 데이터를 리턴 count() RDD의 값 갯수를 리턴 top(num) 상위 num 갯수만큼 리턴 takeOrdered(num) (Ordering) Ordering 기준으로 num 갯수만큼 리턴한다. reduce(func) RDD의 값들을 병렬로 병합 연산
- 기록된 모든 작업을 실제 수행하는 연산자 (Return = 데이터 또는 실행 결과)
- Transformation:
- Lazy Evaluation 느긋한 연산:
- 즉시 실행하지 않는 것
- Action 연산자를 만나기 전까지는 Transformation 연산자가 아무리 쌓여도 처리하지 않음
- Hadoop의 Map Reduce와 차이점
- (장점) Spark는 데이터 처리 시, 불필요한 중간 연산 줄이고, 전체 작업을 최적화하여 성능 극대화
- DAG를 사용해 Spark는 전체 작업을 분석하고, 최적화된 실행 계획을 수립
- Hadoop은 각 단계마다 중간 결과를 디스크에 저장하므로 성능 느릴 수 있음
- Spark는 메모리에서 필요한 작업만 수행, 중간 데이터 저장 및 로드 비용 절감, 성능 향상
DataFrame
- DataFrame의 등장 배경
- RDD 의 문제점, 성능적 이슈
- RDD는 메모리나 디스크에 저장 공간이 충분치 않으면 제대로 동작 X
- 스키마 (데이터베이스 구조) 개념 부재 = 구조화된 데이터와 비구조화 데이터 함께 저장 시 효율성 저하
- RDD는 기본적으로 직렬화와 Garbage Collection 사용 → 메모리 오버헤드 증가
- 직렬화: 데이터를 배포하거나 디스크에 데이터를 기록할 때마다 JAVA 직렬화 사용
- Garbage Colletion: 사용하지 않는 객체를 자동으로 메모리에서 해제
- RDD는 별도의 내장된 최적화 엔진 부재 → 사용자가 각 RDD는 직접 최적화 필요 (e.g. 테이블 조인 효율화)
- Spark의 DataFrame
- 행과 열로 구성된 데이터 분산 컬렉션 (Pandas 의 DataFrame과 유사)
- Spark v1.3부터 도입됨
- 기존 RDD와의 차별점
- 구조화된 structed 데이터 구조
- DataFrame은 구조화된 데이터를 쉽게 다루기 위해 만들어진 데이터 구조
- SparkSQL 등을 통해 구조화된 데이터 쿼리 처리 가능
- Garbage Collection (GC) 오버헤드 감소
- RDD는 데이터를 메모리에 저장
- DataFrame은 데이터를 오프-힙(gc 영향을 받지 않는, 디스크가 아닌) RAM 영역에 저장
- 직렬화 오버헤드 감소
- 오프-힙 메모리를 사용한 직렬화를 통해 오버헤드 감소
- Flexibility & Scalability
- DataFrame은 CSV, 카산드라 등 다양한 형태의 데이터 직접 지원
- 구조화된 structed 데이터 구조
- Dataframe의 transformation, action 연산 분류
- RDD에서의 transformation, action 의 작동 원리와 동일하게 DataFrame의 transformation, action 도 작동함
| transformation | action |
| distinct() | show() |
| withColumn() | collect() |
| withColumnRenamed() | count() |
| filter(), where() | take() |
| groupBy() | reduce() |
| agg(sum,min,max,count...) | first() |
| select() | describe() |
| selectExpr() | explain() |
| union(),unionAll() | |
| sort(), orderBy() | |
| drop() |

Dataset
- 타입이 지정된 구조화된 데이터 컬렉션으로, DataFrame과 RDD의 장점을 결합한 구조
- Spark v1.6에서 도입
- Spark 2.0에서는 DataFrame API가 Dataset API와 통합됨
- DataFrame은 Dataset[Row]로 표현
References
https://dbrang.tistory.com/1639
https://pseudo-lab.github.io/data-engineering-for-everybody/docs/6_data_processing_frameworks_2/6.2_Apache-spark.html
https://sunrise-min.tistory.com/entry/Apache-Spark아파치-스파크
https://artist-developer.tistory.com/8
https://m.blog.naver.com/tajogood/220783546981
https://medium.com/@leeyh0216/spark-internal-part-1-rdd의-내부-동작-d50eb7a235e6
https://spidyweb.tistory.com/312
https://wikidocs.net/28377
https://jiwon94.tistory.com/12
https://velog.io/@ehwnghks/Spark-transformation-vs-action