LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
날짜: 2025년 1월 16일
- https://openreview.net/forum?id=UQJ7CDW8nb
- ICLR 2025 under review
- 깃허브가 살짝 유명함
- 대규모 멀티모달 모델을 MLLM, VLM 이라고 안하고 LMM이라고 함
- aihub 서버를 사용해야하는 상황인데 gpu 메모리가 32기가라 LLaVA 경량 방안을 알아보고 있는 중 (LLaVA 7b 기준 batch 1로 학습해도 37기가 이상 점유)
- 근데 이 논문은 작게 서빙(추론)할 수 있는거에 의의가 있지 학습에는 오히려 학습할거 더 많아서 사용은 보류.. (추론 성능이 좋은 것 같음, 특히 비디오 추론에서 좋은 것 같음)
- 기존에 읽었던 논문들 이외에도 작년(2024) 초 쯤에 나온 TinyLLaVA, MoE-LLaVA 등을 읽어볼 예정
Abstract
- 실시간 대규모 멀티모달 모델(LMM)
- LMM 프레임워크: 시각적 입력을 비전 토큰(연속 표현)으로 인코딩하고 이를 대규모 언어 모델(LLM)의 맥락에 통합
- 대규모 파라미터와 많은 맥락 토큰(주로 비전 토큰)은 상당한 계산 부담을 초래
- 효율적인 LMM을 위한 이전 노력은 항상 LLM 백본을 더 작은 모델로 교체하는 데 초점, 토큰 수의 중요한 문제를 간과
- 최소한의 비전 토큰을 가진 효율적인 LMM인 LLaVA-Mini를 소개
- 비전 정보를 보존하면서 비전 토큰의 높은 압축 비율을 달성하기 위해 LMM이 비전 토큰을 이해하는 방식을 분석
- 대부분의 비전 토큰이 시각 정보를 텍스트 토큰에 융합하는 초기 계층에서만 중요한 역할을 한다는 사실을 발견
- LLM 백본에 전달되는 비전 토큰을 하나의 토큰으로 극단적으로 압축
- LLaVA-Mini는 576개의 비전 토큰 대신 단 1개의 비전 토큰만으로 LLaVA-v1.5보다 우수한 성능
- LLaVA-Mini는 FLOPs를 77% 줄이고, 40밀리초 이내의 저지연 응답을 제공하며, 24GB 메모리의 GPU 하드웨어에서 10,000프레임 이상의 비디오를 처리 가능
1. Introduction
- 대규모 멀티모달 모델(LMMs):
- 대규모 언어 모델(LLM)에 시각적 정보를 이해할 수 있는 능력을 부여
- LMM은 시각적 정보를 나타내기 위해 LLM의 맥락에 많은 비전 토큰을 통합
- 계산 복잡성이 크게 증가
- 예) CLIP ViT-L/336px → 24 × 24 = 576개의 비전 토큰으로 인코딩
- LMM의 계산은 주로 모델의 규모와 입력 맥락의 토큰 수에 의해 결정
- 기존 LMM 효율성을 개선하기 위한 접근 방식은 일반적으로 모델에 초점
- 다운사이징, 양자화 기술
- 일부 토큰 감소 방법: 비전 인코더가 출력하는 토큰의 수를 줄이기 위해 미리 정의된 규칙에 의존
- 시각 정보가 손실되고 성능 저하가 불가피하게 발생
- 기존 LMM 효율성을 개선하기 위한 접근 방식은 일반적으로 모델에 초점
- foundational question: LMM(특히 LLaVA 아키텍처)는 비전 토큰을 어떻게 이해하는가?
- 층별 분석(layer-wise analysis), 비전 토큰의 중요성이 LLM의 서로 다른 층에서 어떻게 변화하는지를 관찰
- 초기 층에서는 비전 토큰이 중요한 역할
- 층이 깊어짐에 따라 비전 토큰에 대한 주의는 급격히 감소, 대부분의 주의는 입력 introductions으로 전환
- 특히, 후반 일부 층에서 비전 토큰을 전부 제거하더라도 LMM은 특정 시각적 이해 능력을 유지
- → 융합 과정을 LLM의 초기 층에서 수행하기보다는 LLM 이전에 수행할 수 있다면, 성능을 희생하지 않고 LLM으로 공급되는 비전 토큰의 수 절감 가능
- 층별 분석(layer-wise analysis), 비전 토큰의 중요성이 LLM의 서로 다른 층에서 어떻게 변화하는지를 관찰
- LLaVA-Mini
- 모달리티 사전 융합 모듈 도입
- LLM에 입력하기 전에 비전 토큰을 크게 압축하는 압축 모듈 사용
- (극단적인 설정) LLM 백본에 입력되는 각 이미지당 단 하나의 비전 토큰만 필요로 하여 고해상도 이미지 및 긴 비디오 처리에 대한 추론 시간과 메모리 소비에서 상당한 이점을 제공
- 실험 결과 (11개의 이미지 기반 및 7개의 비디오 기반 이해 기준)
- 576개의 비전 토큰 대신 단 1개의 비전 토큰을 사용하여 LLaVA-v1.5(Liu et al., 2023b)와 비슷한 성능을 달성
- 계산 효율성(77% FLOPs 감소) 및 GPU 메모리 사용량(360 MB → 0.6 MB per image) 측면에서 상당한 이점을 제공
- 이미지 이해의 추론 대기 시간을 100 ms에서 40 ms로 감소
- NVIDIA RTX 3090에서 메모리 24GB로 10,000프레임(3시간 이상)을 초과하는 긴 비디오 처리 가능
2. Related Work
- 대규모 다중 모달 모델(LMMs)
- 비전 인코더를 사용하여 이미지를 비전 토큰으로 변환하고, 이후 대형 언어 모델(LLMs)로 처리
- LMM이 실시간 애플리케이션(OpenAI, 2024a)에 점점 더 많이 배포됨에 따라, 이들의 효율성을 향상시키는 것이 중요한 문제
- 모델 크기를 감소시키거나 LMM에 공급되는 토큰의 수를 줄이는 데 중점
- LMM의 모델 크기를 줄이기 위해
- 이전 방법들은 LLM 백본을 더 작은 것으로 직접 대체하여 총 파라미터 수 줄임
- 매개변수의 크기와 정밀도를 줄이는 것은 LLM 모델의 기능에 영향
- 시각적 작업에서 성능 저하
- LMM 비전 토큰의 숫자
- 고해상도 이미지와 비디오를 처리할 때 상당
- 토큰 병합, PruMerge: 유사성에 따라 비전 토큰을 집계하여 20%에서 50%의 압축률을 달성
- Qwen-VL, MQT-LLaVA: Q-former 또는 리샘플러를 활용하여 비전 토큰을 고정 길이로 압축
- 그러나 이러한 방법은 비전 토큰을 직접 줄이며, 필연적으로 시각적 정보의 손실을 초래
- 비디오 기반 LMM
- Video-ChatGPT, VideoChat, Video-LLaVA, Video-LLaMA: 다양한 길이의 비디오에서 고정된 수의 프레임을 선택
- MovieChat: 메모리 기법을 적용하여 비디오를 고정 길이 표현으로 압축
- VideoLLM-online: 긴 비디오를 처리하면서 프레임당 1개의 토큰을 추출
- 이러한 프레임 선택 또는 병합 방법은 일부 중요한 프레임을 잃거나 비디오의 시간적 정보를 잘못 이해 가능성
- LLaVA-Mini
- 비전 토큰과 텍스트 토큰이 LLM 모델 내에서 어떻게 상호작용하는지를 탐구
- 비전 토큰의 극단적인 압축을 가능하게 하는 모달리티 사전 융합 모듈을 도입
- 성능을 유사하게 유지하면서(LLaVA에 1개의 비전 토큰을 공급) 비전 토큰을 압축
3. How does LLaVA understand vision tokens?
- 시각적 이해를 보존하면서 비전 토큰을 압축하기 위해 LMM이 비전 토큰을 이해하는 방식 탐구
- 초기 분석: LLaVA 아키텍처에 집중, LMM에서의 비전 토큰(특히 그 양)의 역할을 주목 기반 attention-based 관점
3.1 LLaVA Architecture
- LLaVA
- 비전 및 언어 처리 능력을 통합한 고급 다중 모달 아키텍처
- 비전 Transformer(ViT)를 시각적 입력에, LLM을 텍스트에 활용하여 주어진 언어 지침 Xq 및 시각적 입력 Xv에 따라 언어 응답 Xa를 생성
- 일반적으로) 사전 학습된 CLIP ViT-L/14 및 프로젝션 레이어 사용, 시각적 입력 Xv를 비전 토큰 Hv로 인코딩
- 비전 토큰 Hv와 언어 지침의 임베딩 Hq가 Vicuna 또는 Mistral과 같은 LLM에 입력되어 응답 Xa 생성
- 실제로 비전 토큰은 종종 언어 지침의 중간에 삽입됨
3.2 Preliminary Analyses
- LMM에서 비전 토큰의 중요성을 분석하여 비전 토큰 압축 전략 진행
- attention-based 관점
- LMM의 각 레이어에서 비전 토큰의 중요성을 평가
- LLaVA-v1.5-Vicuna-7B, LLaVA-v1.5-Vicuna-13B, LLaVA-v1.6-Mistral-7B, LLaVA-NeXT-Vicuna-7B (Liu et al., 2023b; 2024b) 등 여러 LMM을 포함하여 다양한 크기와 훈련 데이터 세트를 가진 모델들 간의 공통 특성을 식별
- 비전 토큰은 초기 레이어에서 더 중요
- 어떤 레이어에서 LMM의 비전 토큰이 더 중요한 역할을 하는지 찾기 위해, 서로 다른 토큰에 배정된 주목 가중치 attention weights를 측정
- 레이어별로 다양한 유형의 토큰(명령어, 비전, 응답 포함)에 할당된 주의 가중치의 변화 (그림2)
- 비전 토큰에 할당된 주의는 레이어에 따라 상당히 다르게 나타남
- 초기 레이어에서는 비전 토큰이 더 많은 주의를 받지만, 이 주의는 깊은 레이어로 갈수록 급격히 감소하여 80% 이상이 명령어 토큰에 집중
- → 비전 토큰이 초기 레이어에서 중심적인 역할을 하며, 명령어 토큰이 주의 메커니즘을 통해 비전 토큰으로부터 관련 비주얼 정보를 탐색하고 있음을 시사
- 개별 비전 토큰의 중요성을 추가로 평가
- 각 레이어에서 entropy of the attention distribution 계산 (그림3)
- 거의 모든 비전 토큰이 초기 레이어에서 폭넓은 주의를 받는 반면
- 후반 레이어에서는 일부 비전 토큰만 집중적으로 주의
- → 초기 레이어에서 중요하며, 그 수를 줄이면 불가피하게 비전 정보의 손실이 발생함을 시사
그림2 (a)
그림3 (a)
- 비전 토큰이 다른 레이어에서 제거될 때 LMM의 비전 이해 능력을 평가
- 우리는 비전 토큰이 레이어 1-4, 5-8, ..., 29-32에서 제거될 때 LLaVA-v1.5의 GQA와 MMBench에서의 성능을 측정
- 초기 레이어에서 비전 토큰을 제거하면 비전 이해 능력이 완전히 상실
- 후반 레이어에서 토큰을 제거하는 것은 모델의 원래 성능을 보존하는데 미미한 영향
- 비전 토큰이 LLaVA의 초기 레이어에서 중요한 역할
4. LLaVA-Mini
- 최소한의 비전 토큰을 가진 효율적인 LMM인 LLaVA-Mini
- LLaVA-Mini는 압축 모듈을 통해 LLM 백본에 입력되는 비전 토큰의 수를 크게 줄입니다
- 압축 과정에서 시각 정보를 보존하기 위해, 비전 토큰이 시각 정보 융합에 중요한 역할을 한다는 이전 연구 결과에 기초
- LLaVA-Mini는 LLM 백본 전에 모달리티 사전 융합 모듈을 도입하여 시각 정보를 텍스트 토큰에 융합
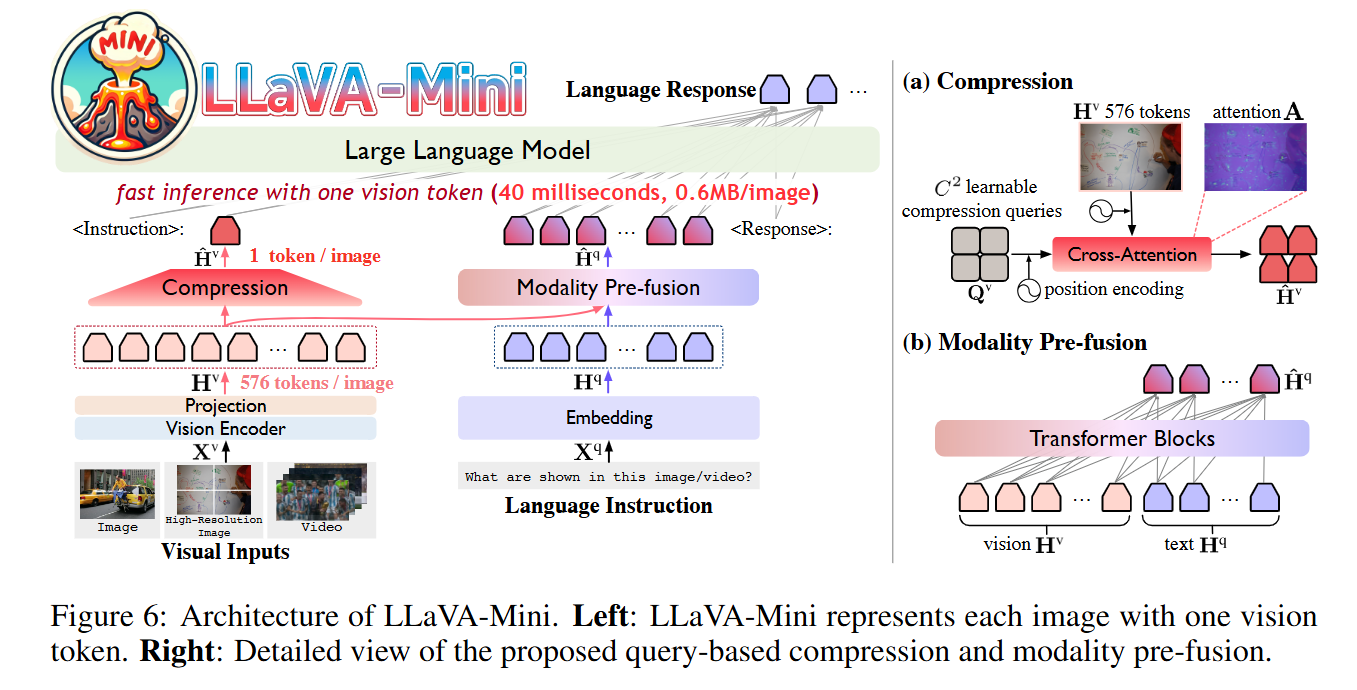
4.1 Architecture
- 시각 입력 Xv에 대해, 사전 학습된 CLIP 비전 인코더를 사용하여 각 이미지에서 시각 특징을 추출
- 투영 레이어를 통해 단어 임베딩 공간으로 매핑, 비전 토큰 $H_v \in \mathbb{R}^{N_2 \times d_h}$을 생성
- $N_2$는 비전 토큰의 수, $d_h$는 LLM의 임베딩 차원
- 언어 instruction $X_q$에 대해서는 LLM의 임베딩 레이어 사용, 텍스트 토큰 표현 $H_q \in \mathbb{R}^{l_q \times d_h}$를 생성
- 비전 토큰 압축
- LLaVA-Mini는 쿼리 기반 압축 모듈을 활용하여 LLM 백본에 입력되는 비전 토큰의 수 줄임
- 비전 토큰의 압축을 학습하기 위해,
- $C \times C$ 의 학습 가능한 압축 쿼리 $Q_v$도입
- 이 쿼리는 cross-attention을 통해 모든 비전 토큰 $H_v$와 상호작용, 중요한 시각 정보를 선택적으로 추출하여 $C \times C$ 압축 비전 토큰 $\hat{H_v} \in \mathbb{R}^{C^2 \times d_h}$을 생성
- 압축 과정에서 이미지의 공간 정보를 보존하기 위해, 학습 가능한 쿼리 및 원래 비전 토큰에 2D 사인 곡선 위치 인코딩 $PE(·)$를 도입
- 💡
- Cross-Attention*
- Cross-Attention*은 딥러닝에서 Transformer 아키텍처에서 사용되는 주요 메커니즘 중 하나로, 주로 두 가지 서로 다른 시퀀스 간의 상호작용을 학습하는 데 사용됩니다. 이는 Self-Attention 메커니즘의 확장 버전으로 볼 수 있으며, Self-Attention이 입력 시퀀스 내에서 자신의 요소들 간의 관계를 학습하는 것과 달리, Cross-Attention은 한 시퀀스의 정보를 다른 시퀀스의 정보와 비교하고 조정하는 데 사용됩니다.
- Cross-Attention은 Query (Q), Key (K), Value (V)의 입력이 서로 다른 두 시퀀스에서 제공된다는 점에서 Self-Attention과 구분됩니다.
- Query (Q): 한 시퀀스에서 생성됨 (예: 디코더의 현재 상태).
- Key (K): 다른 시퀀스에서 생성됨 (예: 인코더의 출력).
- Value (V): Key와 같은 시퀀스에서 생성됨 (예: 인코더의 출력).압축 쿼리는 전체 비전 토큰 Hv에서 중요한 시각적 정보를 선택적으로 추출하는 역할을 합니다. Cross-Attention을 사용하면 다음과 같은 이유로 효율적입니다:
- 이를 통해 Query 시퀀스가 Key-Value 시퀀스의 중요한 정보에 집중하도록 학습합니다.
- 정보의 가중 집중:
- Cross-Attention은 쿼리 (Qv)와 입력 토큰 (Hv) 사이의 유사도를 계산하여 중요한 시각적 정보에 높은 가중치를 부여합니다.
- 이를 통해 압축 과정에서 중요한 시각적 패턴이나 특징만을 선택적으로 유지할 수 있습니다.
- 학습 가능한 쿼리 (Qv):
- Qv는 학습 가능한 매개변수로, 모델이 데이터에서 학습하면서 어떤 정보가 중요한지 동적으로 결정합니다.
- 이는 정적인 압축 기법(예: 단순 다운샘플링)보다 훨씬 유연하고 효율적입니다.
- 모달리티 사전 융합 Modality Pre-fusion
- 비전 토큰의 압축은 불가피하게 일부 시각 정보 손실을 초래
- 압축 과정에서 가능한 한 많은 시각 정보를 보존하기 위해,
- 시각 정보와 텍스트 정보를 미리 결합하는 모듈을 추가
- 시각 정보(vision tokens)와 텍스트 정보(text tokens)를 결합(Concatenate)한 후, 사전 융합 모듈 통과
- 이 모듈은 Transformer 블록으로 구성되며, LLM 본체와 동일한 구조와 설정을 사용
- 결합된 결과에서 텍스트와 관련된 시각 정보가 포함된 융합 토큰(fusion tokens) 생성
- 압축된 비전 토큰 $\hat{H}_v$과 융합된 텍스트 토큰 $\hat{H}_q (C_2 +l_q)$을 LLM에 입력으로 넣어, 응답 생성
- = 최종적으로 LLM에는 "압축된 시각 토큰"과 "융합된 텍스트 토큰(시각 토큰, 텍스트 토큰 결합)"이 모두 입력
4.2 High-Resolution Image and Video Modeling
- LLaVA-Mini는 시각 정보를 나타내기 위해 최소 비전 토큰을 사용하여 고해상도 이미지와 비디오를 효율적으로 처리
- 고해상도 이미지
- LMM의 해상도는 일반적으로 시각 인코더에 의해 결정
- 예) CLIP의 ViT-L은 336×336 픽셀의 해상도로 인코딩
- 더 높은 해상도의 이미지를 인식하기 위해, 이미지를 수평 및 수직으로 각각 두 부분으로 나누어 네 개의 하위 이미지로 분할
- 이러한 각 하위 이미지는 시각 인코더와 프로젝션에 의해 개별적으로 처리, 고해상도의 672×672 픽셀을 가진 $N^2 \times 4$ 비전 토큰을 생성
- 제안된 압축 모듈: $N^2 \times 4$ 비전 토큰을 $\hat{H}_v$라는 $C_2$압축 비전 토큰으로 줄이는 데 사용
- 모달리티 사전 융합 모듈: 4개의 하위 이미지, 원본 이미지, 언어 instruction을 입력받아 융합 토큰 $\hat{H}_q$ 생성
- LLM에 입력된 토큰의 수는 $C_2+l_q$
- 고해상도 이미지를 처리할 때는 세부정보를 더 많이 보존하기 위해 ( C )가 표준 해상도 설정보다 약간 더 높게 설정
- LMM의 해상도는 일반적으로 시각 인코더에 의해 결정
- 비디오
- LMM는 종종 비디오에서 여러 프레임을 추출 → 상당한 계산 비용 초래
- 예) LLaVA-v1.5의 경우, 8초 비디오에서 초당 1프레임(fps)으로 프레임을 추출, 576×8 = 4608 비전 토큰이 생성
- LLaVA-Mini는 최소 비전 토큰으로 각 이미지를 표현할 수 있어 긴 비디오를 처리하는 데 큰 이점을 제공
4.3 Training
- LLaVA-Mini는 LLaVA와 동일한 두 단계로 이루어진 훈련 과정과 동일
- 1단계: 비전-언어 사전 훈련
- 압축 및 모달리티 사전 융합 모듈이 아직 적용되지 않습니다 = $N^2$ 비전 토큰 변경 전
- LLaVA-Mini는 시각 캡션 데이터를 사용하여 비전과 언어 표현을 정렬하는 방법을 학습
- 훈련은 프로젝션 모듈에만 집중되며 시각 인코더와 LLM은 고정
- 2단계: Instruction Tuning
- LLaVA-Mini가 최소 비전 토큰을 기반으로 다양한 시각 작업을 수행하도록 훈련
- 압축 및 모달리티 사전 융합이 LLaVA-Mini에 도입, 고정된 시각 인코더를 제외한 모든 모듈(즉, 프로젝션, 압축, 모달리티 사전 융합 및 LLM 백본)은 end-to-end 방식으로 훈련
5. Experiments
5.1 Experimental Setting
- 벤치마크: 11개의 이미지 벤치마크와 7개의 비디오 벤치마크에서 실험 수행
- 베이스라인: 이미지/비디오 LMM이므로 여러 고급 이미지 기반 및 비디오 기반 LMM과 비교
- 구성:
- LLaVA-Mini는 LLaVA-v1.5와 같은 설정을 사용
- 비전 인코더로 CLIP ViT-L/336px를 사용하고 LLM 백본으로 Vicuna-v1.5-7B를 사용
- 동일한 훈련 데이터를 사용
- 압축 하이퍼파라미터 C는 1로 설정 (비전 토큰을 하나의 토큰으로 압축)
- 모달리티 프리퓨전 레이어 수 $N_{fusion}$을 4로 설정
- 해상도가 672x672 픽셀인 고해상도 버전은 LLaVA-Mini-HD로 표시
- 압축 하이퍼파라미터 C는 8로 설정되어 64개의 비전 토큰으로 압축
- 비디오 처리를 위해 LLaVA-Mini는 초당 1프레임(1 fps)을 추출하고 C=1로 설정
- LLaMA-3.1-8B-Instruct를 LLM 백본으로 사용하는 변형 소개
- LLaVA에서 665K 이미지 instruction 데이터, Video-ChatGPT에서 100K 비디오 instruction 데이터 및 일부 오픈 소스 데이터를 결합하여 300만 훈련 샘플을 생성
- 8대의 NVIDIA A800 GPU를 사용하여 훈련
(부럽다)
- LLaVA-Mini는 LLaVA-v1.5와 같은 설정을 사용
5.2 Main Results
- 이미지 기반 평가:
- LLaVA-v1.5와 비슷한 성능을 보이면서도 576개의 비전 토큰 대신 오직 1개의 비전 토큰만 사용
- 이전의 LMM: 비전 인코더 다음에 유사한 토큰들을 직접 병합, 시각 정보의 손실 발생, LMM의 시각 이해에 부정적인 영향
- 비디오 기반 평가
- LLaVA-Mini는 전반적으로 우수한 성능
- 비디오 LMM(VideoChat, Video-LLaVA, Video-LLaMA): 각 프레임을 나타내기 위해 훨씬 더 많은 비전 토큰을 사용, 이에 따라 LLM의 제한된 컨텍스트 길이로 인해 비디오에서 8-16개의 프레임만 추출, 일부 프레임에서 시각 정보가 손실
- 긴 영상으로의 확장
- LLaVA-Mini를 긴 형식의 비디오 벤치마크인 MLVU 및 EgoSchema와 비교
- LLaVA-Mini는 Video-ChatGPT 교육 데이터에만 훈련
- 긴 비디오 데이터에 노출되지 않았기 때문에 긴 비디오에서의 성능은 완전히 그 구조의 길이 외삽 능력에서 파생
- LLaVA-Mini는 긴 비디오 이해에서 상당한 이점
5.3 Efficiency
- LLaVA-Mini가 제공하는 계산 효율성을 추가로 탐구
- 계산 부하, 추론 지연 시간 및 메모리 사용 면에서의 장점
- FLOPs는 calflops(Ye, 2023)로 계산
- 지연 시간은 어떤 엔지니어링 가속 기법도 사용하지 않고 A100에서 테스트
- FLOPs 및 추론 지연 시간
- LLaVA-Mini는 LLaVA-v1.5에 비해 계산 부하를 77% 줄임
- 2.9배의 속도 향상
- 응답 지연 시간을 40ms 이하로 유지
- 높은 해상도로 모델링할 때 LLaVA-Mini의 효율성이 더욱 두드러져 82%의 FLOPs 감소와 3.76배의 속도 향상
- 메모리 사용량
- LMMs의 또 다른 도전 과제로, 특히 비디오 처리에 있어 중요
- 이론적으로 RTX 3090(24GB)에서 10,000프레임 이상의 비디오 처리 지원 가능
6. Analyses
6.1 Superiority of Modality pre-fusion
- 제안된 모달리티 사전 융합: 시각 정보를 텍스트 토큰에 미리 통합하여 비전 토큰의 극단적인 압축 가능
- ablation study 수행
- 사전 융합 없이 토큰 압축을 수행할 경우, 144개의 비전 토큰을 유지하더라도 성능이 약 5% 저하
- = 과거의 토큰 병합 방법들이 종종 낮은 성능을 보이는 이유
6.2 Effect of Compression
- 비전 토큰에 대한 높은 압축 비율을 달성하기 위해 쿼리 기반 압축을 사용
- 쿼리 기반 압축과 직접 평균 풀링의 성능을 비교
- 쿼리 기반 압축은 추가적인 계산 비용을 최소한으로 요구하면서 이미지의 중요한 특징을 적응적으로 포착할 수 있어 상당한 이점
6.3 Performance with Various Vision Tokens
- LLaVA-Mini는 표준 이미지에는 1개의 비전 토큰을, 고해상도 이미지에는 64개를 사용
- 비전 토큰 수를 더 늘릴 때 LLaVA-Mini의 잠재력을 탐구
- 비전 토큰 수가 증가함에 따라 LLaVA-Mini의 성능이 계속 개선
- 576개의 비전 토큰을 사용할 때 LLaVA-v1.5를 초과 성능
- 계산 자원이 풍부할 때의 효과성을 입증
6.4 Case study
- LLaVA-Mini는 웹사이트 스크린샷에서 가격 정보 (OCR)를 정확히 식별하는 등 시각적 세부 사항을 효과적으로 포착
- LLaVA-Mini는 각 프레임당 단 하나의 비전 토큰만 사용함으로써 1fps의 속도로 비디오를 처리
- Video-LLaVA는 비디오 길이에 관계없이 비디오당 8프레임을 추출
- → 축하 장면을 주어진 경우, Video-LLaVA는 축하 전에 “한 무리의 남성들이 필드에서 축구를 하는” 장면을 잘못 상상



