
목차
2. "Llama-3.1-8B-Instruct" 폴더 생성
최근에 라마3.1이 공개되었죠
저도 지금 진행 중인 연구에 활용하기 위해서 라마3.1을 사용해보려고 합니다
(서버 세션을 다시 띄우면서 올라마 설치 및 라마3.1 설치 등을 전반적으로 다시 해야하는 겸..해서 포스팅을 합니다 ㅎㅎ)
아직 저도 잘 모르지만,, 과정을 작성해보려고 해요 ㅎㅎ
기본적으로 테디노트 "#llama3 출시🔥 로컬에서 Llama3-8B 모델 돌려보기👀" 영상을 따라가며 진행됩니다 (아래 영상 첨부)
다만 이 내용을 그대로 llama3.1로 적용하고 리눅스 서버에서 올라마를 사용해볼게요
https://www.youtube.com/watch?v=12CuUQIPdM4
0. Ollama 다운 및 설치
아래 명령어로 설치해주세요 (다운하고 실행되는 명령어)
https://ollama.com/download/linux
Download Ollama on Linux
Download Ollama on Linux
ollama.com
curl -fsSL https://ollama.com/install.sh | sh
1. 깃 클론
아래 레퍼지토리를 클론해주세요 (가장 간단한 것 같습니다)
https://github.com/teddylee777/langserve_ollama
GitHub - teddylee777/langserve_ollama: 무료로 한국어🇰🇷 파인튜닝 모델 받아서 로컬 LLM 호스팅. LangServe
무료로 한국어🇰🇷 파인튜닝 모델 받아서 로컬 LLM 호스팅. LangServe, Ollama, streamlit + RAG - teddylee777/langserve_ollama
github.com
2. "Llama-3.1-8B-Instruct" 폴더 생성
클론해준 레퍼지토리의 ollama-modelfile 폴더에 "Llama-3.1-8B-Instruct" 폴더를 생성해줍니다
저는 아래와 같은 위치에 생성해두었어요
3. Modelfile 복제 및 수정
저는 Llama-3-8B-Instruct를 사용했었어서 이 폴더에 있는 Modelfile을 복제해서 "Llama3.1-8B-Instruct"폴더에 이동시켜주었습니다.
그 다음 Modelfile의 가장 윗 줄을 수정해주었습니다. ( 3 -> 3.1)

4. QuantFactory/Meta-Llama-3.1-8B-Instruct-GGUF 다운
영상에 나온 같은 작성자의 GGUF 파일을 다운하였습니다.
이미 올려두셨더라구요. (아래 링크 첨부)
다운 위치는 "Llama3.1-8B-Instruct"폴더입니다
터미널을 사용해서 다운하셔도됩니다
저의 경우 Q8을 사용했습니다.
(Q8_0: 8비트 양자화된 모델을 의미.)
저도 정확히는 아직까지 양자화 Quantization 개념이 확실치 않는데.. Q8은 8비트로 양자화에서 작고, 더 빠른 대신 정확도가 살짝 손실될 수도 있다는 것으로 알고 있습니다.
원본 모델은 16비트 또는 32비트이구용
아래 양자화에 대해 설명해주신 분이 계셔서 첨부해봅니당
https://huggingface.co/QuantFactory/Meta-Llama-3.1-8B-Instruct-GGUF/tree/main
QuantFactory/Meta-Llama-3.1-8B-Instruct-GGUF at main
huggingface.co

wget https://huggingface.co/QuantFactory/Meta-Llama-3.1-8B-Instruct-GGUF/resolve/main/Meta-Llama-3.1-8B-Instruct.Q8_0.gguf
https://data-newbie.tistory.com/992
LLM) Quantization 방법론 알아보기 (GPTQ | QAT | AWQ | GGUF | GGML | PTQ)
양자화 기술은 모델을 압축하여 빠르고 효율적으로 만드는 기술입니다. 모델의 가중치와 활성화 값을 줄여 메모리를 절약하고 연산 속도를 높입니다. 이 글은 여러 양자화 기술
data-newbie.tistory.com
5. ollama serve
로컬에다가 설치할 경우, 그냥 바로 ollama create ~ 해도 되는데 서버에다가 설치할 경우에는, serve 과정이 필요합니다.
(Ollama 애플리케이션이 클라이언트 요청을 수신하고 처리할 수 있도록 서버를 실행 필요)
저는 Ollama 서버가 백그라운드에서 실행되도록 아래 명령어를 사용하여 가동시켜주었습니다.

nohup ollama serve &
6. ollama create llama3.1-instruct-8b -f Modelfile
그 다음 ollama create ~를 입력하면 잘 실행되고 있는 모습
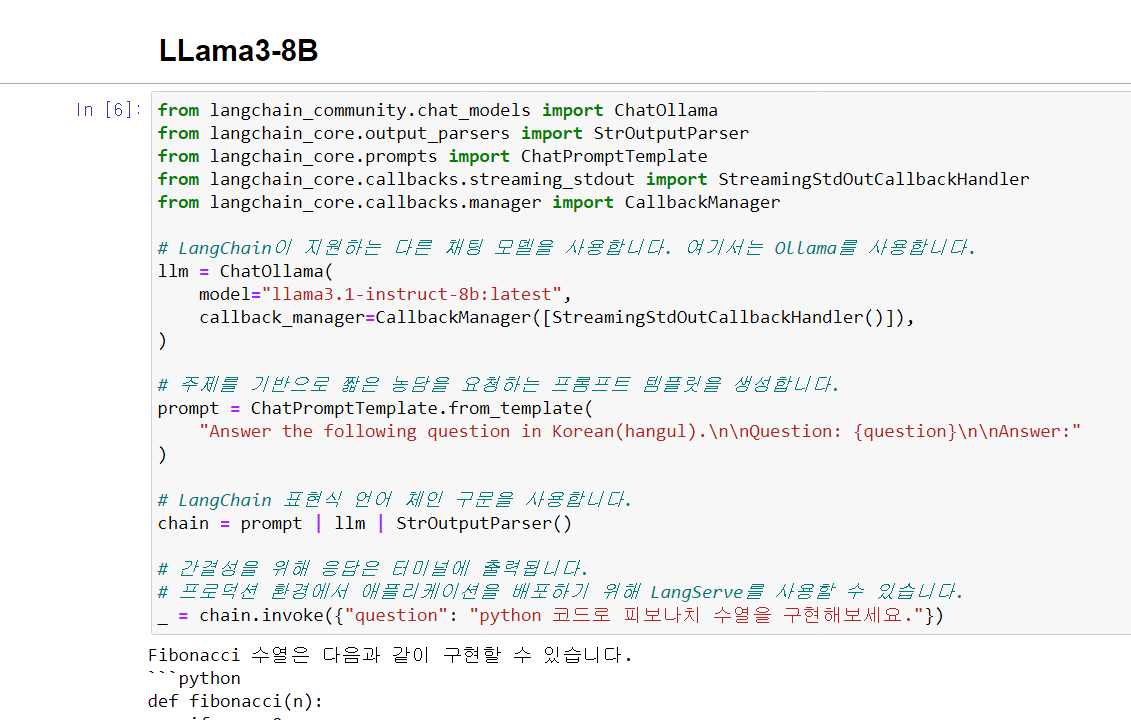
이를 클론해둔 langserve_ollama의 eample폴더 안에 있는 00-ollama-test 파일로 테스트도 해볼 수 있습니다.
보면 ChatOllama에서 3.1 로 모델명을 바꿔주시면 새로 설치한 3.1 모델이 잘 돌아가는 것을 확인하실 수 있습니다.


'Development > etc.' 카테고리의 다른 글
| 허깅페이스 모델 업로드하기 (feat. lfs 큰 용량 파일) (2) | 2024.11.04 |
|---|---|
| [논문 탐색하는 법] 인공지능융합학과 대학원 3기가 사용 중인 방법들 (7) | 2024.09.10 |
| AI HUB 안심존 오프라인 센터 (서울, 서초) 방문 후기 (환경 세팅법, 사용 방법 등) (3) | 2024.02.24 |
| AI HUB tar 파일 다운 및 압축해제 하기 (tar → part → tar.gz → wav) (3) | 2024.01.07 |
| 패스트캠퍼스 30개 사례로 배우는 Anomaly Detection 알고리즘 구현과 실전 프로젝트 듣는중.. (1) | 2023.12.15 |



