Visual-RFT: Visual Reinforcement Fine-Tuning
날짜: 2025년 3월 6일
- https://arxiv.org/pdf/2503.01785
- 허페 daily 1등 했던 논문인데 (지금은 phi4에 밀려서 2등 되긴 했는데..) Visual 쪽으로 RFT 논문 자체가 별로 없어서 읽어보았습니다 :)
- 논문 고도화해서 졸업 논문으로 Visul RFT + TTC 쪽으로 쓰려고 해서 읽는 중입니다.
- deepseek R1 을 포함해서 요즘 추론용 모델들이 핫해지면서
- 강화학습 쪽이 완전 핫해졌어용..
- 강화학습 왜 해,, 라고 생각했는데 제가 하게 되었네용..
- 강화학습 스터디도 할 예정..! (일 벌리기 달인 ^^)
- 대박인데
- 의문인점은 이런식으로 비교하는 게 맞을까 싶음
- 강화학습에 중점된 학습 방식으로 강화학습과 지도학습을 비교하는 것이라..
- 그래도 선도적인 연구..!
- TTC 도 곧 정리할게용..
Abstract
- 강화 학습 미세 조정(Reinforcement Fine-Tuning, RFT)
- 답변에 대한 피드백을 학습
- 미세 조정 데이터가 부족한 애플리케이션에서 특히 유용
- 다중 모달 도메인에서의 적용은 아직 탐색되지 않음
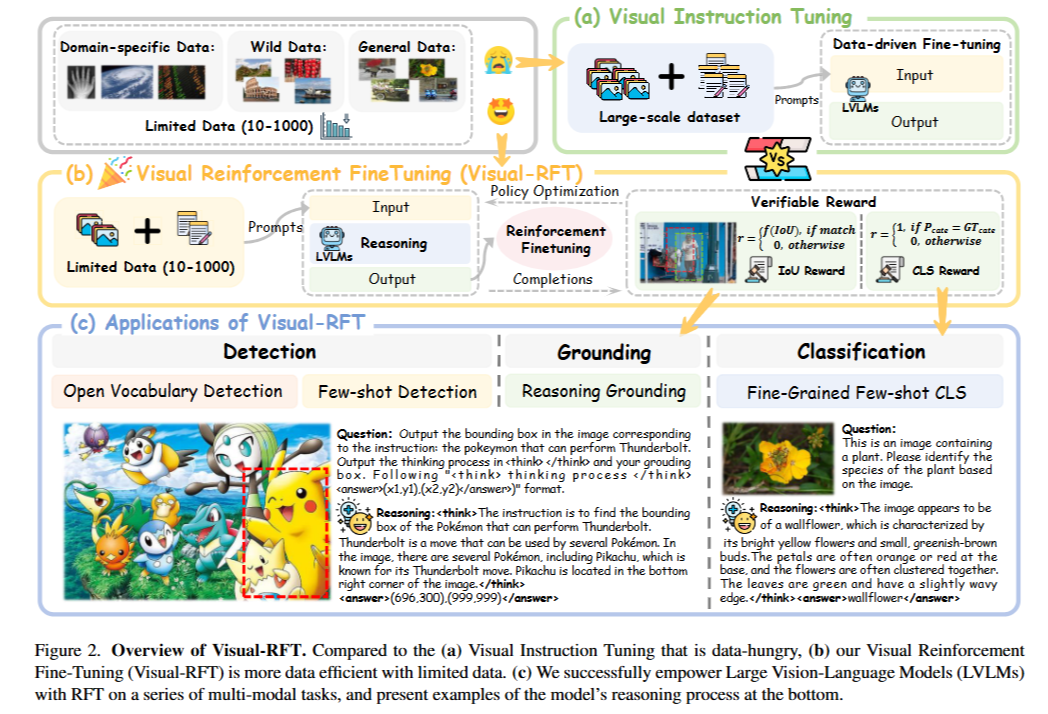
- Visual Reinforcement Fine-Tuning(Visual-RFT)를 소개
- 대형 비전-언어 모델(LVLMs)을 사용하여 입력에 대한 추론 토큰과 최종 답변을 포함하는 여러 응답을 생성
- 제안된 시각 인식 검증 가능한 보상 함수를 사용하여 정책 최적화 알고리즘(예: 그룹 상대 정책 최적화)으로 모델을 업데이트
- 객체 탐지를 위한 교차 유형(IoU) 보상, 다양한 인식 작업에 대한 서로 다른 검증 가능한 보상 함수를 설계
- 성능
- 세밀한 이미지 분류, 몇 샷 객체 탐지, 추론 그라운딩 및 개방 어휘 객체 탐지 벤치마크
- Supervised Fine-tuning(SFT)와 비교하여 Visual-RFT의 경쟁력 있는 성능
- 도메인 특정 작업에 대해 사고력과 적응성을 향상시키는 데이터 효율적이고 보상 주도적인 접근 방식을 제공
1. Introduction
- 대형 추론 모델(Large Reasoning Models, LRM)
- 답변하기 전에 더 많은 시간을 “생각”하도록 설계
- OpenAI o1
- 단지 수십 개에서 수천 개의 샘플로 모델을 효율적으로 미세 조정
- 도메인 특정 작업에서 뛰어 나는 성능을 발휘하는 강화 학습 미세 조정(RFT)
- DeepSeek R1과 같은 최근의 오픈 소스 연구는 o1을 재현, 검증 가능한 보상(Verifiable Rewards) 사용
- 강화 학습
- 보상 점수: 선호 데이터에 대해 훈련된 개별 보상 모델에 의해 예측되는 것이 아니라, 미리 정의된 규칙에 의해 직접 결정
- RFT와 SFT간의 차이: 데이터 효율성
- 기존 SFT: 고품질의 선별된 데이터의 “정답”을 직접 모방, 많은 양의 훈련 데이터에 의존
- RFT: 모델의 반응을 평가, 맞는지에 따라 조정, 시행착오를 통해 배우도록
- 데이터가 부족한 도메인에서 특히 유용
- 이전의 일반적인 생각: RFT가 과학(예: 수학) 및 코드 생성과 같은 작업에만 적용된다는 것
- (수학과 코딩은 명확, 객관적인 최종 답변이나 테스트 케이스를 보여주어 보상이 상대적으로 확인하기 간단하기 때문)
- 본 논문: RFT가 수학 및 코드 도메인을 넘어 시각적 인식 작업에도 적용. 비주얼 강화 미세 조정 (Visual-RFT)을 소개
- Visual-RFT의 구현 세부사항 제시
- 각 입력에 대해 대형 비전-언어 모델 (LVLMs)을 사용
- 추론 토큰과 최종 답변을 포함하는 여러 응답(경로)을 생성
- 정책 최적화를 위해, 작업별 규칙 기반 검증 가능 보상 함수를 정의
- SFT와 대조
- Visual-RFT: 다양한 가능한 솔루션을 탐색, 검증된 보상 함수로 정의된 원하는 결과를 최적화하는 방법을 학습
- 정의된 답변을 단순히 모방하는 것이 아니라 최적의 결과를 발견하는 것
- SFT에서 데이터 확장으로 학습 패러다임을 전환, 특정 다중 모달 작업에 맞춘 변수를 가진 보상 함수의 전략적 설계로 전환
- 검증 가능한 보상과 시각적 인식 능력(예: 탐지, 기초, 분류)의 시너지 결합
- 모델이 새로운 개념을 빠르고 데이터 효율적으로 습득
- 세밀한 추론 과정에 의해 촉진
- 각 입력에 대해 대형 비전-언어 모델 (LVLMs)을 사용
- Visual-RFT의 효과성을 검증
- fine-grained image classification
- one-shot: 극히 제한된 데이터(예: 약 100 샘플), 비주얼-RFT는 기준선보다 24.3% 더 정확도를 향상, SFT는 4.3% 감소
- few-shot: 최소한의 훈련 데이터로도 기존의 SFT에 비해 우수
- reasoning grounding
- LISA 데이터셋(=추론 중요 데이터셋): 성능 좋음, GroundedSAM와 같은 전문 모델 초월
- open vocabulary object detection
- LVIS의 희귀 카테고리를 포함하여 새로운 카테고리로 인식 기능을 신속하게 전이
- 특히 2B 모델 성능 향상
- Visual-RFT의 강력한 일반화 능력, 시각 인식 및 추론을 향상시키는 데 있어 강화 학습의 중요한 역할을 강조
- fine-grained image classification
- 기여점
- Visual Reinforcement Fine-tuning (Visual-RFT)을 소개. 제한된 데이터를 사용하는 시각 인식 작업에서 효과적인 검증 가능한 보상으로 강화 학습을 확장
- 효율적이고 높은 품질의 보상 계산을 가능. DeepSeek R1의 스타일 강화 학습을 LVLM에 전이. 다양한 시각 작업을 위한 검증 가능한 보상을 설계.
- 다양한 시각 인식 작업(세밀한 이미지 분류, 소수 샷 객체 탐지, 추론 기초 및 개방 어휘 객체 탐지)에 대해 광범위한 실험을 수행
- 훈련 코드, 훈련 데이터 및 평가 스크립트를 Github에 완전히 오픈 소스
2. Related Work
- Large Vision Language Models (LVLMs)
- LVLM의 훈련은 두 단계로 진행: (a) pre-training(사전 훈련) and (b) post-training(사후 훈련)
- supervised fine-tuning and reinforcement learning 포함
- 사후 훈련: 모델의 응답 품질, 지시 따르기 및 추론 능력을 개선하는 데 중요
- LLM의 사후 훈련에서 RFT에 대한 연구 존재, LVLM에서는 부족
- 본 논문: GRPO 기반 강화 알고리즘과 검증 가능한 보상 사용
- LVLM의 훈련은 두 단계로 진행: (a) pre-training(사전 훈련) and (b) post-training(사후 훈련)
- Reinforcement Learning
- 추론 모델 등장, 강화 학습(RL) 기법으로 점점 더 확대
- 많은 연구: 수학 문제 해결, 코딩과 같은 추론 작업에서 LLMs 성능 향상
- Deepseek-R1-Zero: 감독학습 세부 조정(SFT) 단계를 없애고 강화학습(RL)만을 사용
- 다중 모달 설정에서의 응용은 제한적으로 탐구
- LVLMs에서의 강화학습
- RL은 주로 환각 완화 및 모델을 인간 선호와 정렬시키는 작업에 사용
- 추론 및 시각적 인식을 향상시키는 연구 부족
3. Methodology
3.1 Preliminary
- Reinforcement Learning with Verifiable Rewards
- 검증 가능한 보상을 활용한 강화 학습(RLVR)
- 수학 및 코딩과 같이 객관적으로 검증 가능한 결과가 있는 작업에서 언어 모델을 향상시키기 위해 설계된 새로운 훈련 접근 방식
- 인간 피드백으로부터의 강화 학습(RLHF)와 다르게, RLVR는 훈련된 보상 모델에 의존 X, 직접적인 검증 기능을 사용
- 작업의 본질적인 정확성 기준과 강력한 정렬을 유지하면서 보상 메커니즘을 단순화
- 입력 질문 q, 정책 모델 $π_θ$는 응답 o를 생성하고 검증 가능한 보상을 받음
- 최적화: $π_{ref}$는 최적화 이전의 참조 모델, R은 검증 가능한 보상 함수, β는 KL 발산을 제어하는 하이퍼파라미터
- 검증 가능한 보상을 활용한 강화 학습(RLVR)
- DeepSeek R1-Zero 및 GRPO
- DeepSeek R1-Zero: 그룹 상대 정책 최적화(GRPO) 프레임워크를 통해 강화 학습
- PPO 강화 학습(=정책 성능을 평가하기 위해 비평 critic 모델)과 다르게,
- GRPO: 후보 응답 그룹을 직접 비교하여 추가 비평 모델의 필요성 제거
- 주어진 질문 q, GRPO는 우선 현재 정책 $\pi_{\theta_{\text{old}}}$로부터 G개의 고유한 응답 {o1, o2, ..., oG}를 생성
- 이러한 응답에 따라 행동, 취하고 얻은 보상을 {r1, r2, ..., rG}로 표시
- 정규화를 위해 그들의 평균 및 표준 편차를 계산, 응답의 상대적 질 판단
- $A_i$: i번째 응답의 상대적 질
- 모델이 그룹 내에서 높은 보상 값을 가진 더 나은 응답을 선호하도록 유도
3.2 Visual-RFT
- 다중 모달 입력 데이터는 이미지와 질문으로 구성
- 정책 모델 $π_θ$: 추론 과정을 출력하고 입력에 기반하여 응답 그룹을 생성
- 각 응답은 검증 가능한 보상 함수를 통과하여 보상을 계산
- 각 출력에 대한 보상의 집합 컴퓨팅 후, 각 응답의 질이 평가되고 정책 모델을 업데이트하는 데 사용
- 정책 모델 훈련의 안정성을 보장하기 위해, Visual-RFT는 KL 발산을 사용하여 정책 모델과 참조 모델 간의 차이를 제한
- Verifiable Reward in Visual Perception
- 선호 정렬 알고리즘과 정렬하는 강화 학습(RL)의 중요한 단계
- 예측과 실제 답변 간의 정확한 일치를 확인하는 검증 함수만큼 간단
- 다양한 비주얼 인식 작업을 위한 서로 다른 규칙 기반의 검증 가능한 보상 함수를 설계
- IoU Reward in Detection Tasks
- 탐지 작업에서는 모델의 출력이 바운딩 박스(bbox)와 해당 신뢰도로 구성
- 탐지 작업에 대한 보상 함수: 평가에서 평균 정밀도(mAP)를 계산하는 데 사용되는 교차 비율(Intersection-over-Union, IoU) 지표를 적절히 고려
- IoU와 신뢰도 기반의 보상 함수 $R_d$를 설계
(식 5, 6)- 모델의 출력 박스와 신뢰도에 대해 이 박스들을 신뢰도에 따라 정렬하여 {b1, b2, ..., bn}이라고 표시
- 각 $b_i$를 실제 진실 바운딩 박스 {bg1, bg2, ..., bgm}과 매칭하고 IoU를 계산하며 IoU 임계값 $\tau$를 설정
- 임계값 $\tau$이하의 IoU를 가진 바운딩 박스는 유효하지 않은 것으로 간주
- 초기 집합에서 각 박스에 대해 IoU와 신뢰도를 얻고 이를 {iou1 : c1, iou2 : c2, ..., ioun : cn}으로 표시
- IoU 결과와 신뢰도를 사용하여 보상 함수 $R_d$를 구성
- 신뢰도 보상 $R_{conf}$는 IoU와 관련
(식 7, 8)- 각 바운딩 박스에 대해 $iou_i$가 0이 아닌 경우, 이는 성공적인 매칭
- 단일 박스의 신뢰도 보상 $r_c$
- 성공적으로 매칭된 박스에 대해 신뢰도가 높을수록 더 좋다는 것을 의미
- 매칭 실패의 경우, 박스에 대한 신뢰도 보상 $r_c$ 가 낮을수록 좋음
- $R_{conf}$ 는 출력의 모든 바운딩 박스에 대한 신뢰도 보상의 평균
- 형식 보상 $R_{format}$ 는 모델 예측이 및 와 같은 요구되는 HTML 태그 형식을 충족하도록 강제하는 데 사용
- CLS Reward in Classification Tasks
- 분류 작업에서 사용되는 보상 함수: 정확도 보상 $R_{acc}$와 형식 보상 $R_{format}$ 두 부분으로 구성
식 9 - 보상은 모델의 출력 클래스와 실제 클래스 비교를 통해 결정
- 올바른 분류에는 1의 값을, 잘못된 분류에는 0의 값을 부여
- 분류 작업에서 사용되는 보상 함수: 정확도 보상 $R_{acc}$와 형식 보상 $R_{format}$ 두 부분으로 구성
- Data Preparation
- Visual-RFT를 훈련하기 위해 다중 모달 훈련 데이터셋을 구축
- 최종 답변을 제공하기 전에 모델이 자신의 추론 과정을 출력하도록 유도하는 프롬프트 형식을 설계
- 감지 및 분류 작업에 사용되는 프롬프트는 표 1
- 구조화된 형식으로 추론 과정과 최종 답변을 출력하도록 유도하기 위해 형식 보상을 사용
- 추론 과정: 모델의 자기 학습 및 강화 미세 조정 동안의 개선에 핵심적, 답변에 따라 결정된 보상은 모델의 최적화 결정
- Visual-RFT를 훈련하기 위해 다중 모달 훈련 데이터셋을 구축
4. Experiments
4.1 Experimental Setup
- Implementation Details
- few-shot learning approach 적용, 적은 수의 샘플(minimal number of samples)로 모델을 학습
- 이미지 분류 및 객체 탐지
- 제한된 데이터에서 강화 학습을 적용
- few-shot setting 사용
- 개방형 어휘 객체 탐지
- 65개의 기본 클래스를 포함하는 세분화된 COCO 데이터셋
- Qwen2-VL-2/7B 훈련, 모델의 일반화 능력 평가
- COCO의 15개의 새로운 클래스와 LVIS의 13개의 희귀 클래스로 테스트
- 먼저 모델에게 이미지에 카테고리가 존재하는지를 확인하라고 요청한 다음, 이미지에 존재하는 카테고리의 경계 상자를 예측
4.2 Few-Shot Classification
- fine-grained image classification
- few-shot
- Flower102, Pets37, FGVC-Aircraft, Car196의 네 가지 데이터셋을 선택
- 수십 개에서 수백 개의 유사 카테고리를 포함, 난이도 증가
- 결과
테이블 2- 단일 샷의 데이터로만도 성능을 크게 향상
- 동일한 최소 데이터 양에서도 SFT는 눈에 띄게 성능이 떨어짐
- 4-shot, 8-shot, 16-shot 설정에서도 RFT 성능 좋다~
4.3 Few-Shot Object Detection
- Few-shot learning
- 전통적인 시각 모델과 대규모 비전-언어 모델(LVLMs)이 직면한 핵심 과제 중 하나
- 강화 미세 조정: 모델이 적은 양의 데이터로 빠르게 배우고 이해, 이 문제에 대한 새로운 해결책을 제공
- 본 연구
- COCO 데이터셋에서 8개 희귀 카테고리 선택: 각 카테고리별로 1, 2, 4, 8, 16개 이미지 제한하여 훈련 세트 구성
- LVIS 데이터셋의 경우 6개의 희귀 카테고리를 선택: 1~10개 이미지
- 10샷 설정으로 근사
- Qwen2-VL-2/7B 모델을 강화 미세 조정 및 SFT를 사용하여 200단계 동안 훈련하여 모델의 학습 능력을 평가
- 결과
테이블 3, 4- RFT후의 모델이 SFT 모델을 큰 차이로 능가, 지속적인 우위를 유지
- 작은 양의 데이터로 강화 학습을 통해 시각 인식 능력이 크게 향상
- 몇 가지 추상적인 도메인 외 데이터셋에 대해서도 추가 테스트
- 다양한 유형의 애니메이션 스타일 괴물 소녀가 포함된 MG(몬스터 걸스) 데이터셋을 선택
- 도메인 외 데이터를 사용함으로써 모델 인식 및 추론의 난이도 증가
- 4샷, 16샷 환경 실험
- 결과: SFT 보다 크게 성능 향상
테이블5
4.4 Reasoning Grounding
- vision-language intelligence의 중요 측면: 사용자 요구를 따르는 것
- 기존 specialized detection systems
- 추론 능력이 부족하고 사용자의 의도를 완전히 이해하지 못함
- LISA 데이터셋: 대형 언어 모델(LLM)이 다른 모델(예: SAM)을 위한 제어 토큰을 출력, 감독 세밀 조정을 통해 경계 상자 좌표를 직접 예측
- Visual-RFT 및 감독 세밀 조정(SFT)을 사용하여 LISA 훈련 세트에서 Qwen2-VL 2B/7B 모델 [38]을 세밀 조정
- 추론 기초 객체가 포함된 239장의 이미지로 구성
- Qwen2-VL이 예측한 경계 상자로 SAM을 통해 분할 마스크를 생성
- 결과
그림5- Visual-RFT는 SFT에 비해 경계 상자의 IoU 측면에서 최종 결과를 상당히 개선
- 사고 과정이 추론 능력과 기초 정확도를 상당히 향상
- Visual-RFT를 통해 Qwen2-VL은 비판적으로 생각하고 이미지를 신중하게 조사하여 정확한 기초 결과를 생성하는 방법을 습득
LISA 데이터셋
4.5 Open Vocabulary Object Detection
- Visual-RFT는 SFT와 달리, 단순히 데이터를 암기하는 것이 아니라 과업에 대한 진정한 깊은 이해
- COCO 데이터셋에서 65개의 기본 카테고리를 포함하는 6K 주석을 무작위로 샘플링
- 데이터를 사용하여 Qwen2-VL-2/7B 모델에서 Visual-RFT 및 SFT를 수행
- 이전에 본 적이 없는 15개의 새로운 카테고리에서 테스트
- 난이도를 높이기 위해, LVIS 데이터셋의 13개 희귀 카테고리에 대해서도 추가 테스트를 실시
- 결과
테이블7, 8- RFT 이후 평균 mAP 성능 향상
- 특히,
- 표 8의 일부 희귀 LVIS 카테고리에 대해 원래 또는 SFT 훈련 모델은 이러한 카테고리를 인식할 수 없어 0 AP를 기록
- RFT 후 모델은 식별할 수 없었던 카테고리(예: 계란 롤 및 이불)를 인식하는 데 있어 질적인 도약
5. Conclusion
- Visual Reinforcement Fine-tuning (Visual-RFT)을 소개
- LVLM의 시각 인식 및 고정 능력을 향상시키기 위해 GRPO 기반 강화 학습 전략을 조정
- 규칙 기반의 검증 가능한 보상 시스템을 활용, Visual-RFT는 수동 라벨링의 필요성을 줄이고 보상 계산을 단순화하여 다양한 시각 인식 작업에서 상당한 개선
- 세밀한 분류, 열린 어휘 탐지, 추론 고정 및 소수 샷 학습 작업에서 뛰어난 성능
- 최소한의 데이터로 감독 Fine-tuning (SFT)을 초과



