R1-Zero’s “Aha Moment” in Visual Reasoning on a 2B Non-SFT Model
날짜: 2025년 3월 20일
- https://arxiv.org/pdf/2503.05132
- 아직 연구 중이라고 함
- Awesome MLLM Reasoning 찾음
- https://github.com/HJYao00/Awesome-Reasoning-MLLM?tab=readme-ov-file
- 거기서 찾은 논문이 본 논문
- open_r1 이라고 huggingface에서 deepseek r1 재현하기 위해 판 레퍼가 있음 https://github.com/huggingface/open-r1
Abstract
- DeepSeek-R1
- 간단한 규칙 기반 보상을 통한 강화 학습 → 복잡한 추론
- 훈련 중에 자기 반성 및 응답 길이 증가, "Aha Moment”
- → 다중 모드 추론으로 확장
- 본 연구
- non-SFT 2B 모델, 다중 모드 추론, ”Aha Moment” 성공적으로 복제한 첫 사례
- Qwen2-VL-2B, SAT 데이터셋 강화학습 적용
- R1과 유사한 추론을 RL을 사용하여 달성하려는 시도의 실패와 통찰을 공유
- 주요 내용
- (1) instruction 모델에 RL을 적용하면 사소한 추론 경로가 발생
- (2) 단순한 길이 보상은 추론 능력을 이끌어내는 데 비효율적
- 아직 연구 중: 초기 탐색에서의 성공, 실패 및 통찰을 공유
1. Introduction
- DeepSeek R1
- 간단한 규칙 기반 유인을 가진 강화 학습(RL): 큰 언어 모델이 복잡한 추론 능력을 자동으로 구축
- ”Aha Moment” : 명시적 감독 없이 고급 추론 패턴이 나타나는 것
- 자기 반성과 훈련 중 모델이 점점 더 정교한 문제 해결 전략을 탐색
- 응답 길이의 자발적인 증가
- 많은 연구 다중 모드 추론으로 이러한 성공을 확장하려고 시도
- 어려움 1: ”Aha Moment”
- 어려움 2: 증가하는 추론 중 응답 길이
- 본 연구: non-SFT 2B model에서 다중 모드 추론 첫 번째 성공적인 복제 제시
- ”Aha Moment”, 길이 증가
- non-SFT 2B model에서 강화 학습 직접 적용, SFT 없이 더 작은 다중모드 모델에서 정교한 추론 능력 유도 가능
- Qwen2-VL-2B 기본 모델에서 시작하여 강화 학습을 직접 수행
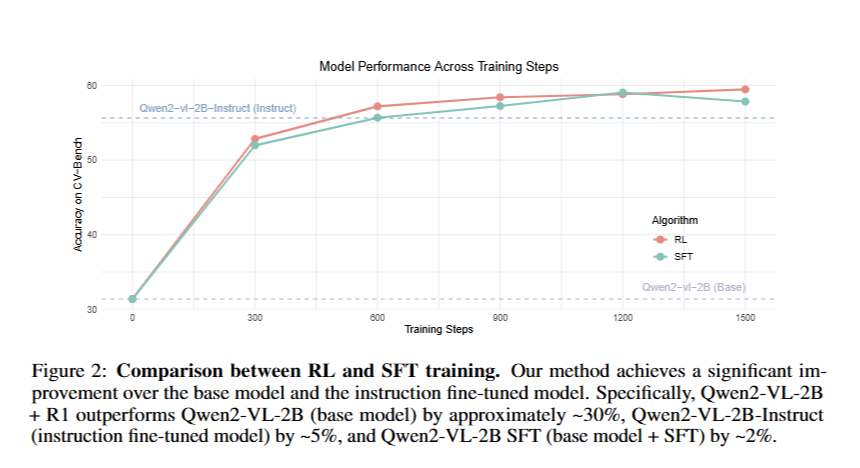
- SFT 없이 본 연구: CVBench에서 59.47%의 정확도를 달성
- 기본 모델보다 약 30% 더 우수
- SFT 모델보다 약 2% 초과
- RL을 사용한 instruction 모델을 통해 R1과 유사한 추론을 달성하기 위한 통찰과 실패 시도를 공유
- SFT된 모델에서 시작할 경우, DeepSeek-R1 복제 실패
- 향상된 성능에도 불구하고, RL을 사용하여 지시 모델에 적용하면 피상적인 추론, 진정한 문제 해결 전략이 아닌 경향
- 순진한 길이 보상은 깊이 있는 추론 능력을 유도하는 데 효과적 X (정확도가 올라가진 않았다)
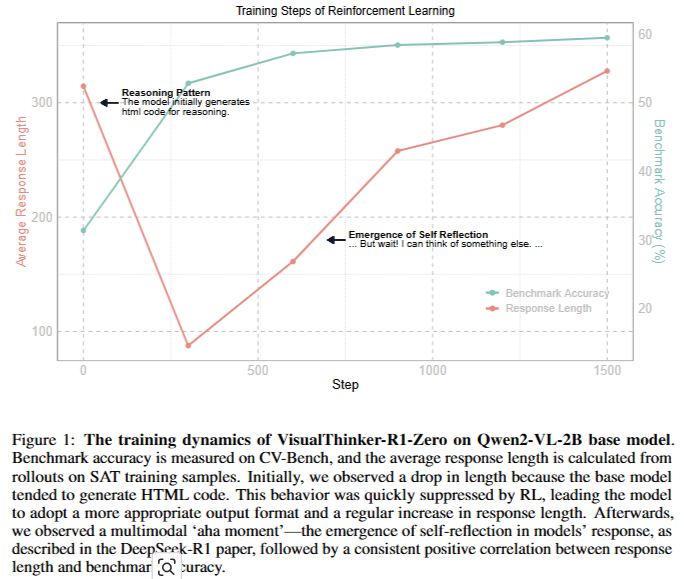
- 기여점
- non-SFT 2B model에서 다중 모드 추론 과제로 R1 성공의 주요 특성인 ”Aha Moment”, 추론 길이 증가 처음으로 복제한 팀
- 시각 중심의 공간 추론 과제가 향상된 추론 능력의 혜택을 받을 수 있음을 증명
- instruction tuned 모델에 RL을 적용하면 피상적인 추론으로 이어진다는 것을 입증
- 오픈 소스화 함
2. Related Works
2.1 Multimodal Reasoning
- LLMs가 향상된 추론 능력을 유도하도록 post trained 할 수 있음을 입증
- 다중 모드 LLM의 추론 능력이 조사
- 일반적으로, 정교한 프롬프트 디자인, 대량의 추론 훈련 데이터 필요
- 연구자들: 광범위한 감독 데이터나 복잡한 프롬프트 기술에 의존하지 않고 모델 성능 향상 방법 개발하는 데 관심
2.2 The "Aha Moment" Phenomenon in DeepSeek R1
- DeepSeek R1
- 강화 학습이 감독된 추론 데이터 없이도 모델의 추론 능력을 유도할 수 있음을 입증
- ”Aha Moment”을 발견: 자율적으로 고급 문제 해결 전략을 개발했으며, 반성(reflection) 및 자기 수정(self-correction)도 포함
- → DeepSeek R1의 성공에 기여한 주요 특성을 요약
- ”Aha Moment”와 응답 길이 증가
- ”Aha Moment”: 훈련 중 모델이 자율적으로 고급 문제 해결 전략을 개발하는 것을 의미
- 응답 길이 증가: 추론 작업을 위해 자연스럽게 더 많은 사고 시간을 배분하기를 학습
- 이런 특성이 없는 다중 모드 복제 모델들(추론용): R1 접근 방식의 유효한 구현으로 간주될 수 있는지는 의문 (wow.. swag…)

3. VisualThinker R1 Zero
- VisualThinker-R1-Zero: non-SFT base model에 RL 훈련을 직접 적용 → ”Aha Moment” 출현
- 시각 중심 과제에서 우수한 성능을 이끌어낸 것을 입증
- Base Model
- Qwen-2-VL-2B를 기본 모델로 활용
- GRPO 적용: 추론 능력을 향상시키기 위해 맞춤형 채팅 템플릿과 프롬프트 전략을 사용
- 기본 모델에 GRPO를 적용하는 것: instruction fine-tuned 모델을 훈련하는 것보다 다중 모드 R1 추론을 복제하는 데 더 효율적이고 효과적인 방법
- instruction fine-tuned 변형인 Qwen-2-VL-2B-Instruct는 상당히 많은 훈련을 요구, ”Aha Moment” 복제 어려움
- Training Recipe
- SAT dataset에 직접 훈련시켜 기본 모델이 데이터셋 Q의 각 질문 q에 대해 다양한 공간 추론 탐구
- 프롬프트 템플릿:
- 사용자와 어시스턴트 간의 대화
- 사용자가 이미지에 대해 질문하고 어시스턴트가 이를 해결
- 어시스턴트는 먼저 자신의 사고 과정을 생각한 후 사용자에게 답변을 제공
- 데이터셋의 각 질문 q에 대해 모델은 이 프롬프트 템플릿을 사용하여 응답 o를 생성, 그러고 나서 RL objective 사용하여 최적화
- RL algorithm
- 기존 레포지토리 (아마 R1-V 말하는듯..) : 미세 조정된 시각 모델 위에 RL을 적용, DeepSeek R1의 주요 특성을 복제하는 데 실패
- 본 연구: non-SFT model에 GRPO를 직접 적용, 추론 경로 연장 및 ”Aha Moment” 경험
- GRPO 알고리즘
- 훈련에 필요한 추가 가치 함수 근사 모델이 PPO에 의해 사용되는 부담을 줄이기 위해,
- GRPO는 정책 모델의 샘플 응답의 평균 보상을 장점 계산 시 기준선으로 채택
- 주어진 입력 질문 q에 대해, 우리는 먼저 응답 그룹 {o1, o2, ···, oG}를 샘플링하고 보상 모델로 해당 보상 {r1, r2, ···, rG}를 계산
- 정책 모델 최적화
- KL 발산(Kullback-Leibler Divergence)을 사용, 새로운 정책(πθ)을 이전 정책(πθold)과 비교
- 새로운 정책이 이전 정책과 얼마나 달라졌는지 측정
- 이 차이가 너무 크지 않도록 조정 = 정책의 업데이트가 지나치게 급격하게 이루어지지 않도록 방지
💡
GRPO(Generalized Policy Optimization)
- 강화 학습에서 정책 최적화 방법 중 하나
- 핵심 아이디어
- 정책(policy): 강화 학습에서 어떤 상황에서 어떤 행동을 할지 정하는 함수
- KL Divergence (KL 발산):
- 두 가지 확률 분포(여기서는 정책이) 얼마나 비슷한지를 측정하는 방법
- GRPO는 현재 정책이 이전 정책과 너무 차이가 나지 않게 업데이트 되도록
- 너무 갑작스러운 변화는 피하고, 점진적으로 개선하는 방식
- PPO (Proximal Policy Optimization)
- GRPO는 PPO와 비슷한 방식으로 동작
- PPO: 정책을 업데이트할 때 변화가 너무 크지 않도록 조절하는 방법을 사용
- 강화 학습에서 정책을 업데이트할 때, 너무 갑작스럽거나 큰 변화가 일어나면 학습이 불안정 → GRPO 이를 방지, 점진적으로 업데이트
- PPO와 GRPO 의 차이
- 정책 최적화 방식과 목표 설정에서 차이
- PPO
- 목표: 정책 업데이트의 안정성 보장
- 클리핑(clipping) 기법을 사용하여, 정책의 비율 변화가 너무 크지 않도록 제한
- GRPO
- KL 발산(Kullback-Leibler Divergence)을 사용하여, 정책 간의 차이를 측정하고, 그 차이가 너무 커지지 않도록 하는 방식
- PPO보다 더 일반적인 방식 (=여러 종류 문제 적용 가능, 유연)
- 정책 간 차이를 좀 더 세밀하게 다룰 수 있는 가능성을 제공
- Reward Modeling
- 보상 모델을 사용하지 않고, 규칙 기반의 보상 함수를 사용
- = 모델이 생성하는 응답의 형식과 정확성에 따라 보상을 부여
- 정확도 보상: 모델의 응답이 최종 답안 제공, 그 답안이 정확하면 +1의 보상
- 형식 보상: 응답이 태그로 사고 과정을 표시, 최종 답안이 태그로 표시되면 +1의 형식 보상
- 그 외의 경우에는 보상은 0
- 규칙 기반 보상 함수는 정책 모델이 빠르게 원하는 형식으로 응답을 생성하도록 도움
4. Experiments
- small non-sft model: 비전 중심의 공간 추론 작업 vision-centric spatial reasoning 해결 가능 입증
- SAT 데이터셋로 모델 훈련: 218,000 개의 질문-답변 쌍으로 구성된 VQA 데이터 세트
- 포토리얼리스틱 물리 엔진을 사용하여 공간 지능을 향상
- 상대적 공간 관계, 상대 깊이 및 객체 수 세기에 관한 질문을 포함하는 정적 하위 집합에 집중
4.1 Evaluation
- CVBench 벤치마크:
- 기본 2D 및 3D 추론 작업에 대한 표준 비전 데이터 세트에서 재활용된 2,638 개의 예제로 구성된 현실적인 비전 중심
- 공간 관계, 객체 수 세기, 깊이 순서 지정 및 상대 거리 평가를 위해 자연어 질문을 형성
- 우리의 레시피가 공간 추론 능력을 얼마나 잘 향상시킬 수 있는지를 체계적으로 검토
4.2 Implementation Details
- 4대의 NVIDIA H100 GPUs (80GB each)
- 훈련 중에 응답 길이 증가를 관찰하기 위해 긴 응답 길이가 필수임을 발견, 최대 응답 길이를 700으로 설정
- non-sft pre-trained mode as the baseline
- compare our method against the base model SFT on the same SAT dataset

4.3 Main Results
- Benchmark Results
- Qwen2-VL-2B non-sft 모델을 미세 조정하고 CV-Bench에서의 성능을 평가
- 모델이 자율적으로 응답 길이를 증가시키는 것을 관찰
- 기본 모델에 RL을 직접 적용했을 때 SFT 방법에 비해 우수한 성능을 보인다는 것을 그림 2에서 관찰
- BLINK와 VSR을 포함한 다양한 공간 추론 데이터 세트
- 우수한 성능을 달성
- SFT로 훈련된 모델과 비교했을 때에도 이점
- Qwen2-VL-2B non-sft 모델을 미세 조정하고 CV-Bench에서의 성능을 평가

- Multimodal Aha Moment
- DeepSeek-R1-Zero의 훈련 중에 관찰된 특히 흥미로운 현상
- 초기 접근 방식을 재고하여 향상된 추론 능력을 위해 자발적으로 추론 전략을 구축
- 본 연구 모델도 재고하는 순간이 있음
- 훈련 중, 모델은 자발적으로 이전 판단을 재검토하고 대안 옵션을 탐색
- 아래 예시

5. Challenges of Applying RL to Supervised Fine-Tuned Models
- RL을 SFT 모델에 직접 적용 실험
- Qwen2-VL-2B-Instruct 모델(감독된 세부 조정 Qwen VL 모델)
- GRPO 알고리즘 적용에 대한 실패 사례를 공유하여 향후 연구에 도움이 될 인사이트를 제공
- 이러한 접근 방식이 효과적인 시각적 추론 모델 구축에 무능력하다는 것을 의미 X
- 감독된 모델에서 시작하는 것의 효과를 발견
- 이 현상의 이유와 함의 조사
- 정교한 추론을 유도하기 위한 시도를 통해 우리의 발견
5.1 Emergence of Trivial Reasoning Patterns
- SFT에 RL을 적용하면 CVBench에서 모델의 성능이 향상
- 의문: 이 방법이 모델에게 더 높은 지능을 달성하도록 유도하는지
- 그림 3: 모델의 응답이 의미가 없거나 사소한 추론 패턴으로 퇴화하는 모습. 사소하고 일반적인 전략 뒤에 태그 안의 질문 특정 응답이 따르는 형태
- 모델이 RL 훈련 동안 진정한 추론 능력을 개발하지 않고 성능을 향상

5.2 Preliminary Investigation of Trivial Reasoning Trajectories
- 예상/가정
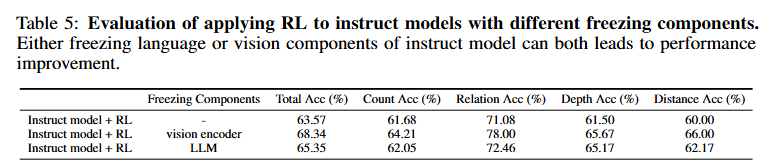
- RL 동안 비전 인코더를 고정할 때 모델이 더 정교한 추론 전략 개발에 집중할 수 있다고 가정
- (반대로) RL 동안 LLM을 고정할 경우 성능은 전체 SFT와 동일할 것이라고 예상
- 결과
- 두 접근 방식 모두 바닐라 구현보다 더 큰 개선을 달성하지만 여전히 짧고 사소한 응답을 생성
- 다중 모달 모델에 대한 RL의 훈련 역학의 복잡성을 시사, 추가 분석 필요
5.3 Failed Attempts with Length Reward
- SFT 모델에서 DeepSeek R1의 추론 능력을 복제하는 데 실패 관찰 이후
- 더 긴 응답에 직접적인 보상을 줘서 더 정교한 추론 패턴을 유도할 수 있는지 조사
- 길이에 기반한 보상 메커니즘을 구현
- 기본 정확도 및 포맷 보상에 추가, 생성된 각 추가 토큰에 대해 +0.001의 보조 보상을 추가
- 결과) 길이가 긴 응답에 단순히 보상을 주는 것은 효과적 X
- emergent reasoning 능력이 지침 조정 모델의 훈련 과정에서 긴 응답 길이를 강제한다고 해서 쉽게 달성될 수 없음을 시사

6. Conclusion
- VisualThinker R1 Zero를 제시
- non-sft 인 Qwen2-VL-2B 모델에 강화 학습을 직접 적용
- “Aha Moment”와 응답 길이 증가 관찰
- 성능 비교, SFT와 비교
- SFT에 RL 적용
- 진정한 문제 해결 전략보다는 사소한 추론 경로를 초래하는 결과



