MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
날짜: 2025년 4월 3일
- https://arxiv.org/pdf/2311.16502
- CVPR 2024 Oral
- 멀티모달 벤치마크 중 추론 벤치마크가 궁금해서 읽어봄
- 아주 대표적인 멀티모달 추론 벤치마크입니다. (테크 리포트에서도 단골손님)
- 거의 추론 수준의 벤치마크는 이 논문처럼 인간을 갈아서? 만드는 논문 많음
Abstract
- MMMU:대학 수준의 주제 지식, 추론 멀티모달 벤치마크
- 6가지 핵심 분야: 예술 및 디자인, 비즈니스, 과학, 건강 및 의학, 인문학 및 사회 과학, 기술 및 공학
- 대학 시험, 퀴즈 및 교과서
- 차트, 다이어그램, 지도, 표, 악보, 화학 구조와 같은 30가지 이미지 유형
- 고급 GPT-4V와 Gemini Ultra조차도 각각 56%와 59%의 정확도만을 달성 → 개선의 여지가 큼
1. Introduction
- 대규모 언어 모델(LLMs)의 빠른 발전 → 인공지능 일반 지능(AGI) 개념 주목
- 일반성(또는 폭)과 성능(또는 깊이) 중심의 AGI를 위한 분류 체계를 제안
- 인간 상위 10% (90%) 수준
- AGI를 측정하기 위한 기준 → 벤치마크
- 다양한 분야의 대학 수준 시험
- MMLU [25] 및 AGIEval [92]: 텍스트 기반 질문
- → 멀티모달의 경우, 고급 추론보다는 상식/일상 지식에 초점
- ScienceQA: 다양한 분야(범위), 깊이 부족(초등학교~중학교 수준)
- → 본 연구, 대학 수준의 다학문 멀티모달 이해 및 추론 벤치마크 MMMU 소개
- MMMU
- 도표 및 표에 이르기까지 다양한 이미지 형식을 다루어 LMM의 지각 능력을 테스트
- 텍스트-이미지 입력이 혼합
- 평가: 28개의 오픈 소스 LMM과 GPT-4V(ision) [60]와 같은 고급 독점 LMM을 평가
- 다양한 분야의 대학 수준 시험
- 기여점(발견)
- MMMU 제안, GPT-4V는 55.7%의 정확도만을 달성 → 개선의 여지가 큼 의미
- 오픈 소스 LMM과 GPT-4V 간에는 성능의 뚜렷한 불균형
- 광학 문자 인식(OCR)이나 생성된 캡션으로 보강된 LLM은 뚜렷한 개선 X → MMMU가 이미지와 텍스트의 더 깊은 공동 해석을 요구
- 시각 데이터가 덜 복잡한 예술 및 디자인, 인문학 및 사회과학과 같은 분야에서는 모델이 더 높은 성능, 반대로 비즈니스, 과학, 건강 의학, 공학 등은 낮은 성능
- GPT-4V의 150개 오류 사례
- 35%의 오류는 지각적 perceptual
- 29%는 지식 부족
- 26%는 추론 과정의 결함
- MMMU는 전문가 AGI에 대한 충분한 테스트가 아니라고 경고
- MMMU에서의 성능 ≠ 인간 상위 10% (90%) 수준
- 대학 시험이 AGI가 수행해야 할 유일한 과제
2. Related Work
- Multimodal Pre-Training
- 초기: LXMERT [71], UNITER [10], VinVL [87], Oscar [37], VilBert [49], VLP [93]
- 이후: CLIP [66], ALIGN [29], SimVLM [78], CoCa [85], Flamingo [2], BLIP-2 [35], Fuyu [6]
- → 지식과 추론이 상대적으로 적게 필요한 작업
- Multimodal Instruction Tuning
- LLaVA [44, 45] 및 MiniGPT-4 [94]: LMM의 instruction following 능력 향상
- 이후 연구: 시각 instruction 데이터 양과 질 향상, 텍스트 및 이미지의 혼합 관리 탐구 등
- LMM Benchmarks
- 기존 벤치마크: 단일 작업 평가 → 일반적인 멀티모달 인식 및 추론능력 포괄적 평가 불충분
- 이후: LMM의 종합 벤치마크 → 여전히 전문가 수준의 도메인 지식이나 깊이 있는 추론 불충분
- 최근:
- MathVista → 수학 영역에 국한
- GAIA → 본 연구와 유사 (모델의 기본 능력인 추론, 멀티모달 처리 또는 도구 사용)
3. The MMMU Benchmark
3.1 Overview of MMMU
- MMMU 벤치마크
- Massive Multi-discipline Multimodal Understanding and Reasoning
- 다양한 전공과 과목의 50명의 대학생(공저자 포함)이 온라인 자료, 교과서 및 강의 자료를 참고하여 자료를 수집
- few-shot 샷 개발 세트, 검증 세트 및 테스트 세트로 구분
- 세 가지 필수 기술인 지각, 지식 및 추론을 측정하도록 설계
- 네 가지 주요 도전을 제시
- 특히, 전문가 수준의 시각적 지각 능력과 주제별 지식을 이용한 심도 있는 추론을 요구하는 도전을 강조
- 텍스트와 이미지를 깊이 이해하고 추론, 고급 다중 양식 분석과 도메인별 지식을 통합 필요


3.2 Data Curation Process
- Data Collection
- 3단계로 구성
- 일반 대학 전공을 살펴보고 어떤 과목이 우리의 벤치마크에 포함될지를 결정
- 이러한 전공에 특화된 50명 이상의 대학생(공저자 포함)을 모집하여 질문 수집을 도와주는 주석자를 배정
- 주요 교과서와 온라인 자료에서 다중 양식 질문을 수집
- 그들의 전문 지식을 기반으로 새로운 질문을 생성
- 저자들은 문제를 쉬움, 보통, 어려움 및 매우 어려움의 네 가지 난이도로 분류
- 매우 쉬움 문제: 10% 정도 → 제외 (본 연구의 목표 부합X)
- Data Quality Control
- 2 단계로 구성
- 어휘 중복 및 출처 URL 유사성을 사용하여 잠재적인 중복 문제를 식별
- 서로 다른 공동 저자들 간에 문제를 배포하여 형식 및 오타 점검을 진행
3.3 Comparisons with Existing Benchmarks
- 폭 Knowledge
- 기존 벤치마크: 일상 지식과 상식에 크게 집중
- 본 연구: 대학 수준의 지식, 30개 이미지 형식 포함
- 깊이 Reasoning
- 기존: 상식 지식이나 단순한 물리적 또는 시간적 추론을 요구
- 본 연구: 대학 수준의 주제 지식으로 심도 있는 추론을 요구

4. Experiments
- LLM과 LMM을 포함한 다양한 모델을 평가
- 폐쇄형 및 오픈소스 모델을 모두 고려
- 제로샷 설정
- 각 모델이 제공하는 기본 프롬프트를 사용
- 제공하지 않는 경우, 주요 실험의 제로샷 설정에 가장 효과적인 프롬프트를 사용
- NVIDIA A100 GPU로 수행
4.1 Baselines
- LMMs
- 최신의 가장 크고 성능이 뛰어난 체크포인트를 사용
- 나열~
- Text-only LLMs
- GPT-4와 여러 오픈소스 LLM이 포함
- MMOCR1에 의한 OCR 또는 LLaVA-1.5에 의한 캡셔닝 사용
- Human Experts
- 90명의 대학 4학년 학생을 참여
- 교과서를 참고하는 것이 허용
- Evaluation
- micro-averaged accuracy 사용
- 체계적인 규칙 기반 평가 파이프라인
- 긴 응답에서 중간 생성물(예: 추론 단계, 계산)의 잠재적 영향을 완화하기 위해, 우리는 강력한 정규 표현식을 구성하고 응답 처리 워크플로를 개발
- 긴 응답에서 숫자 및 결론 구와 같은 주요 구문을 추출하기 위해 사용되어 정확한 답변 매칭 도움
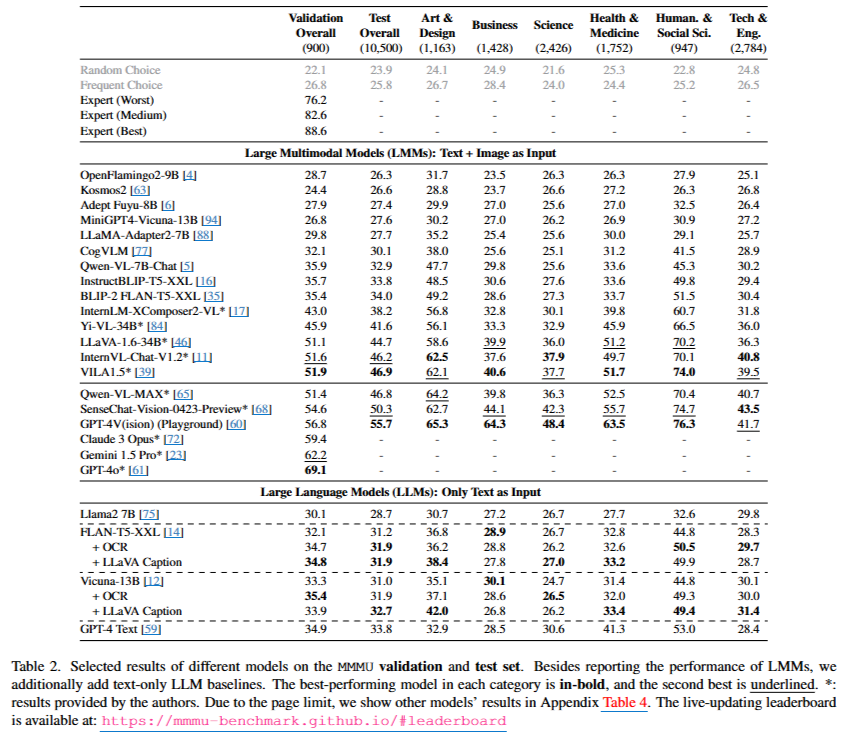
4.2 Main Results
- 주요 발견
- Challenging Nature of MMMU: 최고의 인간 전문가가 88.6%의 검증 정확도를 달성, 모든 모델보다 좋음
- Disparity between Open-source Models and Closed-source models
- 오픈소스 모델들이 GPT-4V보다 성능 ↓
- 최근 공개된 오픈소스 모델은 성능 향상 ↑
- Effectiveness of OCR and Captioning Enhancements
- OCR 및 캡셔닝 기술의 적용은 텍스트 전용 LLM의 성능 개선 X
- 텍스트와 시각적 정보를 효과적으로 해석하고 통합할 수 있는 모델을 요구
- Model Performance across Different Disciplines
- 예술 및 디자인, 인문학 및 사회과학과 같은 분야: 이미지가 natural해서 적은 추론, 높은 성능
- 과학, 건강 및 의학, 기술 및 공학과 같은 분야: 복잡한 추론, 낮은 성능
- MMMU 벤치마크: 멀티모달 이해와 추론의 진전과 도전 과제를 모두 강조
- GPT-4V가 성능 우위
- 그러나 복잡한 시각적 입력과 주제 지식이 요구되는 도메인에서 개선의 여지가 상당
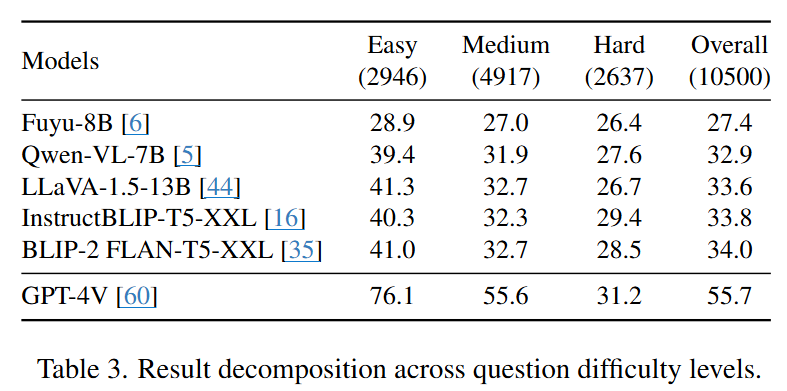
4.3 Analysis on Images Types and Difficulties
- Different Image Types
- GPT-4V는 다른 모델을 크게 초월
- 오픈소스 모델:
- 훈련 중 더 자주 접한 사진과 그림에서 강항 성능
- 기하학적 형태, 악보, 화학 구조와 같은 덜 일반적인 이미지 범주에서 낮은 성능

- Different Difficulty Levels
- 세 가지 난이도 수준 비교
- 난이도가 올라갈수록 GPT-4V와 격차 줄어듦
- → 전문가 수준의 도전적인 질문을 처리하는 데 한계
5. Error Analysis and Future Work
- GPT-4V의 오류 분석
- 무작위로 샘플링된 150개의 오류 사례
- 전문가 주석자에 의해 분석 → 잘못된 예측의 근본 원인 식별
- 지각 오류 (35%), 지식의 부족 (29%), 추론 오류 (26%), 기타 오류
- 추가 연구 분야를 강조
- 1) 언어와 비전의 상호작용: 언어는 시각적 이해를 더 설명하기 쉽게 만들 수 있지만, 환각을 야기하기도 함
- 2) 기준화 grounding의 도전: 시각적 입력 내에서 특정 요소를 기준화하거나 참조하는 작업 GPT-4V 모델에서도 여전히 어려운 문제
- 3) 복잡한 추론은 여전히 도전적: 모델은 여전히 긴 추론 사슬이나 광범위한 계산이 포함된 복잡한 추론 시나리오에서 실패

6. Conclusion
- MMMU의 도입: 전문가 AGI의 맥락에서 LMM의 능력을 평가하는 중요한 진전
- 숙련된 성인에 대한 기대와 일치하는 포괄적인 벤치마크를 제공
- 한계) 수동 큐레이션 → 편향, AGI 테스트 충분 X



