R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization
날짜: 2025년 4월 17일
- https://arxiv.org/pdf/2503.12937
- Mulberry 저자 후속 논문
- Mulberry는 학습 데이터셋 제안, 지도 학습 모델
- 이 논문은 Mulberry로 강화학습한 모델
- https://github.com/jingyi0000/R1-VL
- key step 추출하는게 엄청 중요한데 아직 공개전.. 며칠전에 보상함수는 공개함
- 멀티모달 강화학습 추론 데이터 포함 시 성능이 저하되는 경향
- 레퍼, 논문 등에서
- → 아마 본인 생각으로는 추론에 대한 보상이 딱히 없어서 그런게 아닌가 싶은
- → 단순히 추론 길이만 늘리게끔 보상한다든지 등
- 이 논문에서는 추론에 대한 보상도 설정했다는 점에서 읽어봄
- 레퍼, 논문 등에서
- 희소 보상 문제가 흥미로운데, 근데 크게 근거가 없달까..
- 추론 과정 (think 토큰 내부)에 보상 주는 논문이 거의 없는데 이 논문은 과정에도 보상을 주는 논문
- 근데 warmup하는것에 있어서 아직 논란?이 있는데 이 논문은 warmup 함
- 근데 또 코드 보니까 의문이 들고.. 모델 돌려보니까 그닥인데.. 뭐.. 그렇습니다.
- 이 논문처럼 딱 보상함수를 쓰려면 mulberry 모델로 warmup 해서 써야함..
- 아직 think 토큰 내부를 건드는 보상 관련된 논문이 없는게 효과가 없기 때문이지 않나.. 싶은데..
Abstract
- MLLM의 추론 능력
- 최근 연구: 고품질의 chain-of-thought (CoT) 추론 데이터에 대한 지도 학습 미세 조정
- 종종 모델이 잘못된 추론 경로가 무엇인지 이해하지 못한 채 성공적인 추론 경로를 모방
- 본 연구: 새로운 온라인 강화 학습 프레임워크인 Step-wise Group Relative Policy Optimization (StepGRPO)을 설계
- 두 가지 새로운 규칙 기반 추론 보상
- Step-wise Reasoning Accuracy Reward (StepRAR): 소프트 키-스텝 매칭 기술을 통해 필요한 중간 추론 단계를 포함하는 추론 경로에 보상을 제공
- Step-wise Reasoning Validity Reward (StepRVR): 추론 완전성 및 논리 평가 전략을 통해 잘 구조화되고 논리적으로 일관된 추론 과정을 따르는 추론 경로에 보상
- StepGRPO로 학습한 MLLM 시리즈인 R1-VL을 소개
- 최근 연구: 고품질의 chain-of-thought (CoT) 추론 데이터에 대한 지도 학습 미세 조정
1. Introduction
- MLLM의 추론 능력
- 고품질의 chain-of-thought (CoT) 추론 데이터에 대해 지도 학습 미세 조정 (SFT)을 사용
- SFT 접근 방식: 긍정적인 추론 경로 (즉, 올바른 답으로 이어지는 경로)에만 초점을 맞추고, 부정적인 추론 경로는 크게 무시
- → 모델이 결함이 있고 잘못된 추론 경로가 무엇인지 이해하지 못한 채 성공적인 추론 경로를 모방
- 본 연구: 모방이 아닌 MLLM의 추론 능력 향상 (모방(SFT)이 아니다 뭐 그런 맥락)
- Deepseek-R1 및 Kimi-1.5:
- reward model의 필요성 제거, rule 기반 보상 함수에 따라 생성된 추론 경로에 보상을 제공
- LLM이 추론 경로 그룹을 생성하고 반복적으로 추론 프로세스를 개선하도록 장려
- → 정답으로 이어지는 추론 경로는 더 높은 보상, 오답으로 이어지는 경로는 더 낮은 보상
- MLLM 적용
- 직관적 아이디어: LLM 온라인 강화 학습 방법을 MLLM에 직접 적용
- Deepseek-R1의 GRPO와 같이, 결과 수준의 보상에만 의존
- → MLLM 추론 학습에서 희소 보상 문제로 어려움을 겪는 경우가 많아 최적의 성능을 얻지 못함,
- 소규모 MLLM은 긴 사슬 추론 정확도와 유효성에서 매우 제한적인 능력, 긍정적/높은 보상을 받을 수 있는 MLLM 생성 추론 경로는 거의 없음,
- 직관적 아이디어: LLM 온라인 강화 학습 방법을 MLLM에 직접 적용
- Deepseek-R1 및 Kimi-1.5:

- 본 연구: 온라인 강화 학습 프레임워크인 Stepwise Group Relative Policy Optimization (StepGRPO) 제안
- 희소한 결과 수준의 보상 외에도 밀도 높은 단계별 추론 보상을 도입하여 이 희소 보상 문제를 해결할 것을 제안
- 추가적인 process reward model을 사용 X,
- 두 가지 새로운 rule 기반 추론 보상 메커니즘: Step-wise Reasoning Accuracy Reward (StepRAR), Step-wise Reasoning Validity Reward (StepRVR)
- 추론 경로에 보상
- StepRAR:추론 경로에 주요 중간 추론 단계(즉, 올바른 최종 솔루션에 도달하는 데 필요한 단계)가 포함되어 있는지 평가, soft keystep matching 기술 사용
- StepRVR: 추론 과정 구성, 논리적 일관성 평가
- 두 가지 주요 이점
- 효과성: 전체 추론 궤적을 따라 풍부하고 세분화된 단계별 추론 보상을 제공
- 효율성: process reward model의 필요성 없애면서 단계별 추론 보상 제공 → 계산 오버헤드 감소
- 기여점
- 새로운 온라인 강화 학습 프레임워크인 StepGRPO를 제안
- process reward model의 필요 없이, 두 가지 새로운 rule 기반 추론 보상 메커니즘 제안
- 제안된 StepGRPO를 통해 뛰어난 추론 능력을 갖춘 일련의 MLLM인 R1-VL을 개발
- R1-VL이 최첨단 MLLM에 비해 우수한 성능
2. Related Work
2.1 Multimodal Large Language Model
- 광범위한 비전-언어 이해 task에서 놀라운 발전
- 다양한 응용 분야에서 시각적 콘텐츠를 이해하고 분석하는 능력
2.2 MLLM Reasoning
- 일반적:
- 고품질의 chain-of-thoughts (CoT) 데이터를 생성하여 MLLM의 추론 능력을 향상
- 지도 학습 미세 조정을 수행
- LLaVA-COT, Mulberry
- 본 연구: 단계별 보상 신호를 통해 추론 능력을 스스로 향상시킬 수 있도록 하는 StepGRPO를 설계
2.3 Reinforcement Learning
- 강화학습: 에이전트가 행동을 취하고 보상을 받으며 장기적인 수익을 극대화하기 위해 정책을 업데이트함으로써 환경과 상호 작용하는 방법을 학습
- 일반적인 RL 방법: (예: Q-learning) 로봇 공학, 게임 플레이(예: AlphaGo) 및 자동 제어에 널리 적용
- LLM 이후: Reinforcement Learning with Human Feedback (RLHF) 인간 선호도 데이터를 사용하여 모델을 미세 조정하는 핵심 기술
- Proximal Policy Optimization (PPO), Direct Preference Optimization (DPO)와 같은 알고리즘 활용
- 응답 생성 시 정렬, 일관성 및 유용성을 개선하기 위해 모델 동작을 안내
- 최근 방법: 간단한 결과 수준의 규칙 기반 보상 함수(즉, 올바른 답변으로 이어지는 추론 궤적은 더 높은 점수로 보상됨)를 사용
- → 효과적이고 신뢰할 수 있는 보상 신호 제공 가능
- → 예: 딥시크 R1 결과 수준 보상을 통한 group relative policy optimization (GRPO)
- 본 연구: 강화 학습을 통해 MLLM의 추론 능력 향상, MLLM의 희소 보상 문제를 효과적으로 해결
3. Method
3.1 Task Formulation
- 정책 모델 $\pi_{\theta}$
- 멀티모달 질문 $Q = { \text{text}, \text{image} }$ → 정책모델 $\pi$: 단계별 추론 궤적 사용하여 응답 c 생성
- 각 작업 후 새로운 상태 $s_{t+1}$은 새로 생성된 작업 $a_t$로 현재 상태 $s_t$를 업데이트
- 목표: 이전 상태를 기반으로 더 나은 작업을 선택하여 추론 품질을 향상시킬 수 있도록 정책 모델 $\pi_{\theta}$를 최적화하는 것
- 상태 $s_t$에서 작업 $a_t$를 수행하기 위한 보상 $r(s_t, a_t, s_{t+1})$
- 작업: 여러 단어 토큰을 포함하는 하나 이상의 문장으로 구성된 추론 단계 생성
3.2 Step-wise Group Relative Policy Optimization
- Step-wise Group Relative Policy Optimization (StepGRPO)을 제안
- 희소 보상 문제를 완화, 간단하고 효과적이며 밀도가 높은 단계별 보상 메커니즘
- (1) 정책 워밍업 단계와 (2) 단계별 온라인 정책 최적화 단계의 두 단계로 구성
- Policy Warm-up
- 정책 모델에 기본적인 추론 기능을 장착 → 강화 학습 전에 적절한 단계별 추론 경로를 생성
- 정해진 추론 경로에서 학습하는 지도학습
- 정책 모델 미세 조정: Chain-of-Thought (CoT) 추론 경로가 있는 멀티모달 데이터 세트 (멀티모달 질문 Q, 단계별 추론 경로 $\tau$ 으로 구성된 데이터 세트 $D_s$
- 입력(문제와 그에 대한 단계별 해석), 정답(추론 경로)
- 정책 모델에 기본적인 추론 기능을 장착 → 강화 학습 전에 적절한 단계별 추론 경로를 생성

- Step-wise Online Policy Optimization
- 각 질문 $Q \in D_s$에 대해 정책 모델 $\pi_{\theta}$이 여러 롤아웃을 통해 M개 추론 궤적 그룹 $ci_i^M$ 생성
- → 제시된 단계별 추론 보상을 사용하여 생성된 각 추론 궤적을 평가하고 보상
- Step-wise reasoning accuracy reward (StepRAR)
- 올바른 중간 추론 단계를 포함하는 추론 경로에 추가로 보상을 제공
- 각 질문 Q에 대해 데이터 세트 $D_s$의 추론 경로 $\tau$에서 핵심 추론 답계 집합 $v={v1, v2.}$ 미리 추출
- 핵심 단계를 최종 솔루션에 직접적으로 기여하는 필수 변수 및 방정식으로 정의
- GPT-4로 핵심 단계 추출
- 중복된 내용을 제거, 핵심 단어만 유지, 동등한 형식 적용
- 소프트 매칭 메커니즘 사용
- 보상 (수식 참고)

- Step-wise reasoning validity reward (StepRVR)
- 논리적으로 구조화되고 일관된 진행을 따르도록 하는 것을 목표
- → 두 가지 핵심 기준: 추론 완전성 $\delta_c$, 추론 논리 $\delta_l$
- 추론 완전성: background analysis(이미지 설명, 맥락 파악), step-by-step reasoning process, 최종 정답
- 추론 논리: 배경 분석 → solution, reasoning → answer
- 보상 (수식 참고)
- 논리적으로 구조화되고 일관된 진행을 따르도록 하는 것을 목표
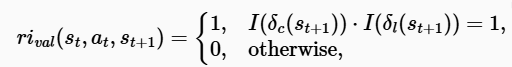
- Optimization with the step-wise rewards
- 전체 보상을 $r_i=r_{iauc}+r_{ival}$로 계산
- 생성된 추론 경로에 대한 보상을 반복적으로 계산
- 그룹에 대한 상대적 보상 정규화 (수식 위 참고)
- 평균 그룹 보상이 baseline으로 $\hat{A}_i$는 $r_i$가 그룹 내의 다른 추론 궤적에 비해 얼마나 더 좋거나 나쁜지를 측정
- 정책 모델 손실 함수(최적화) (수식 아래 참고)
- KL divergence: 정책 모델을 정규화하여 참조 모델에서 과도하게 벗어나는 것을 방지
- 참조 모델: (일반적으로 정책 모델과 동일한 모델로 초기화) 강화 학습 중에는 freeze

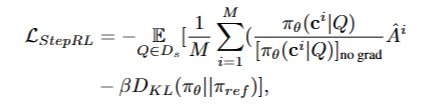

4. Experiment
4.1 Datasets
- 정책 모델 warm-up: Mulberry-260k으로 지도 학습 (Supervised Learning) 미세 조정
- Step-wise: Mulberry-260k에서 10K 데이터를 무작위로 샘플링
- 평가 데이터셋: 8개 멀티모달 벤치마크
4.2 Implementation Details
- 베이스 모델: Qwen2-VL-2B, Qwen2-VL-7B
- Step-wise:
- 질문당 4개의 롤아웃(M = 4)을 수행
- 샘플링 온도를 1.2로 설정: 다양한 추론 경로 장려
- 최대 시퀀스 길이는 L = 1024
- 매치 점수 계수 α 0.1
- KL divergence 계수 β 0.04
- (H100 80GB 4개에서 배치크기 4)
4.3 Main Experimental Results

- R1-VL vs 직접 적용 GRPO
- GRPO를 기준 모델에 직접 적용 → 희소 보상 문제로 인해 성능 저하 발생
- StepGRPO: Qwen2-VL-2B보다 4.6%, Qwen2-VL-7B보다 8% 향상
- → StepGRPO: 단계별 추론 정확도 및 유효성 보상을 도입, MLLM의 희소 보상 문제를 효과적으로 완화하는 데 크게 기인
- R1-VL vs SOTA MLLM
- 추론 집약적인 벤치마크 MathVista 성능 입증
- → StepGRPO: 단순히 긍정적인 추론 경로를 모방X, 추론 능력을 효과적으로 향상
- R1-VL vs 폐쇄형 모델
- 오픈소스 MLLM 이외에도 폐쇄형 모델에 비해 경쟁력 있는 결과
- 거의 GPT-4o 정확도에 거의 근접
4.4 Ablation Study
이하 생략..



