
모든 내용을 포함하고 있지 않습니다.
필요&중요 포인트만 요약한 내용입니다. (발표자료였음)
논문 기본 정보
SAX-ARM: Deviant event pattern discovery from multivariate time series using symbolic aggregate approximation and association rule mining
- 2020
- Expert Systems with Applications
배경
- 데이터
- 금속 가공 제조 데이터
- 다변량 (10개 변수)
- 1,437 길이
- 목적
- 이상탐지
- 이상 패턴 (시계열 서브시퀀스) 간의 연관성 찾기
- 예) 온도가 낮은 이상치 보였을 때 압력의 높은 이상치를 보인다.
프레임워크
1.INT: 정규화
2.SAX: 차원 축소를 통해 평균값으로 요약, 일정한 길이의 세그먼트로 분할
3.SBGen: 시점을 기준으로 이상치 패턴 시계열 그룹화
4.ARM: 그룹화된 이상치 패턴간의 연관 규칙 탐색

1. INT
- 정규화 normalization 변환
- PAA, SAX와 같은 시계열 표현 방법: 시계열의 경험적 분포가 특정 확률 분포를 따른다고 가정
- 수집된 시계열의 분포는 각각 정규, 로그 정규, 감마, 포아송, 웨이불 등 다양한 확률 분포 따름
- 적절한 정규화 변환 필요
- PAA, SAX와 같은 시계열 표현 방법: 시계열의 경험적 분포가 특정 확률 분포를 따른다고 가정
- z-score 정규화 기법
- 시계열 분포가 치우친 skewed 경우 z-score 정규화 분포도 치우치게 됨
- Box-Cox 변환
- Box-Cox 변환된 분포가 정규 분포처럼 보이지만 원래 분포의 분위값이 그대로 유지된다는 것을 설명하기 어려움
- INT
- 표분 분포를 정규 분포로 변환하는 비모수 변환 중 하나
- 임의의 분포를 정규 분포로 근사적으로 변환 가능, 원래 분포의 분위수를 보전 가능
- 특히 데이터가 심각하게 왜곡되어 있거나, 이상치의 영향을 받는 경우에 유용하게 사용하는 기법

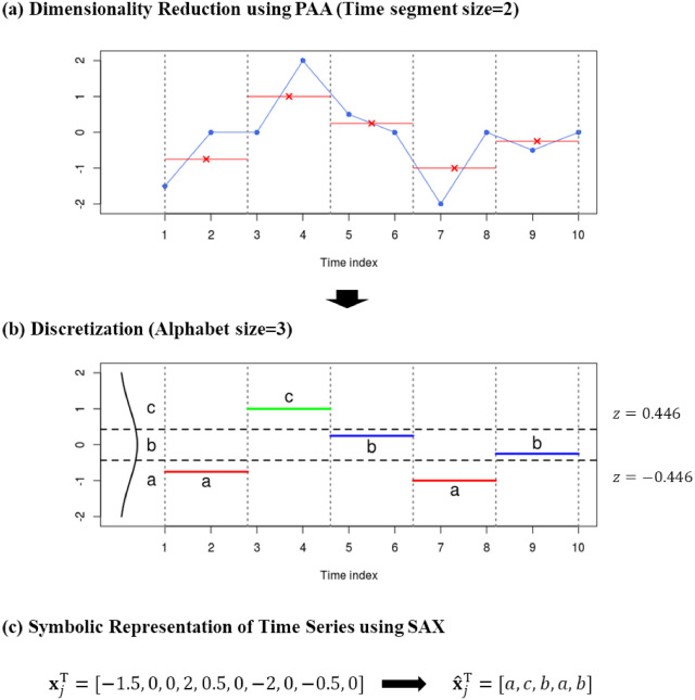
2.SAX
- PAA
- 차원 축소
- 일정한 길이의 세그먼트로 분할
- 평균값으로 요약
- time segment=시계열 subsequence 길이
- 예시의 경우 time segment =2
- 이산화
- 세그먼트의 평균값에 따라 시계열의 각 세그먼트에 적절한 알파벳을 할당
- Alphabet size=표현 개수
- 예시의 경우 Alphabet size=3
- 본 논문의 초점
- 이상 현상
- 상위 10%, 하위 10% 이상현상 정의
- 이에 해당하는 알파벳만 추후에 사용
- 예를 들어 10개의 알파벳(A-J)이면 A와 J만 활용
3.SBGen
- Symbol Basket Generation Algorithm
- ARM 알고리즘을 적용하기 전에 트랜잭션과 유사한 구조화된 데이터를 준비
- 기호화된 다변량 시계열을 포함하도록 설계된 트랜잭션과 유사한 데이터 구조로서 기호 바스켓이라는 새로운 데이터 구조를 제안
- 기호 바스켓: 시간 축을 따라 구성
- 모든 변수에서 동일한 시간 세그먼트에서 발생한 이상 데이터(이상 현상)를 포함

4.ARM
- 연관 규칙
- A라는 사건과 B라는 사건 간의 연관성
- 생성된 규칙을 평가하는 대표적인 척도는 지지(support), 신뢰(confidence) 및 해제(lift)
- 지지도 support
- 전체 거래 중 항목 A와 B가 동시에 발생하는 거래의 비율을 의미
- 신뢰도 confidence
- 항목 A가 주어졌을 때 항목 B가 동시에 발생할 조건부 확률
- 해제 lift
- A가 주어지지 않았을 때의 B의 발생 확률에 비해 A가 주어졌을 때 B가 발생할 확률이 얼마나 증가하는지
- A와 B의 독립성 여부를 평가
- 지지도 support



