모든 내용을 포함하고 있지 않습니다.
필요&중요 포인트만 요약한 내용입니다. (발표자료였음)
특히 공분산 교차에 대해 주로 작성됨
(여러 시계열 n개 (n값은 변동)를 하나의 표현으로 만드는 것에 관심이 있는 요즘..)
논문 기본 정보
Parallel deep prediction with covariance intersection fusion on non-stationary time series
- Science Direct, Knowledge-Based Systems (IF 8.8)
- 2021년, 26회 인용
- 키워드
- Time series prediction
- Deep learning
- Information fusion
- Multiple models
Introduction
- 시계열 예측
- 어려움: 비선형 및 비고정 특징 때문에 어려움에 직면
- 기존 예측 방법
- 1. 통계적 방법
- 2. 머신러닝 방법
- 3. 하이브리드
- 한계
- 복잡한 데이터 특징의 활용 및 적용 범위, 여러 모델의 적응 능력, 멀티클래스 결과에 대한 융합 전략 등 예측 정밀도를 높이는 데는 여전히 문제 有
- 제안
- 무작위 데이터 세트의 생성 -> 모델 훈련 및 선택을 포함한 여러 모델의 병렬 메커니즘 -> 융합
- 여러 모델로 예측을 하여 예측값을 융합하는 것이 한 개의 모델이 예측하는 것보다 좋은 성능을 보임
방법론
- 프레임워크
- 4단계
- 샘플 생성, 분해, 예측 및 융합
- 하나의 모델 예측하는 것이 아닌 여러 모델로 예측한 뒤 예측값을 fusion(융합)하는 방식
- 4단계

1. 샘플 생성
- 데이터셋을 여러 개의 서브시퀀스, 시계열로 샘플링 및 생성

2. 분해
- 시계열 특징값(추세, 주기, 잔차)
3. 예측 모델
- 딥러닝, GRU 네트워크

4. CI (Covariance intersection) 공분산 교차
- 병렬 모델 (여러 모델)로 예측한 결과를 fusion 융합하는 단계
- 설명
- 각 예측값의 분산 융합에 따라 분산이 가장 작은 결과를 얻는 방식
- 여러 추정치들 사이의 불확실성을 최소화하는 통합된 추정치와 공분산을 찾는 것
- 칼만 필터에서 사용되는 알고리즘
- 강점
- 데이터 사이의 상관관계를 몰라도 적용 가능
- 불확실성 감소
- 수식
- 알고 있는 정보 a,b -> 정보 c로 융합
- 평균 a^, b^과 공분산 A,B를 알고 있을 때,
- 통합된 공분산 C, 통합된 평균 c^
-
- 공분산 C를 최소화하는 방식으로 선택됨
- 트레이스(trace) 또는 공분산 행렬의 로그 결정식(log-determinant)과 같은 선택된 노름을 최소화하는 과정ω: 가중치 파라미터, 0~1의 범위

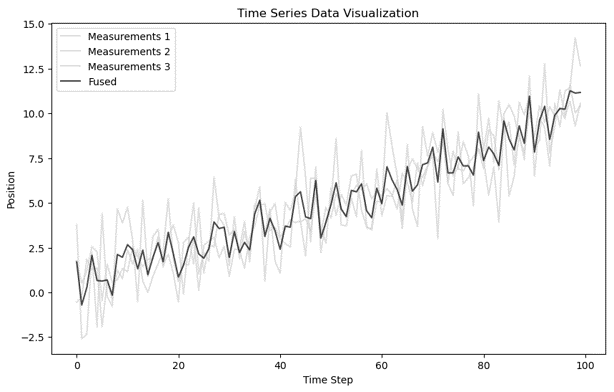
- 예시 데이터
- 각 step(지점)마다 통합된 추정치 계산하여 시각화 (모든 스텝 공분산 교차 계산)
- (본 논문에서는) 12 step 마다 예측(계산)하는 방식
- 예시 데이터의 경우 numpy를 통해 간단 구현한 시계열이며 prediction이 아니기 때문에 매 step 마다 단순하게 CI를 적용해본 것